Language models often need more exposure to fruitful mistakes during training, hindering their ability to anticipate consequences beyond the next token. LMs must improve their capacity for complex decision-making, planning, and reasoning. Transformer-based models struggle with planning due to error snowballing and difficulty in lookahead tasks. While some efforts have integrated symbolic search algorithms to address these issues, they merely supplement language models during inference. Yet, enabling language models to search for training could facilitate self-improvement, fostering more adaptable strategies to tackle challenges like error compounding and look-ahead tasks.
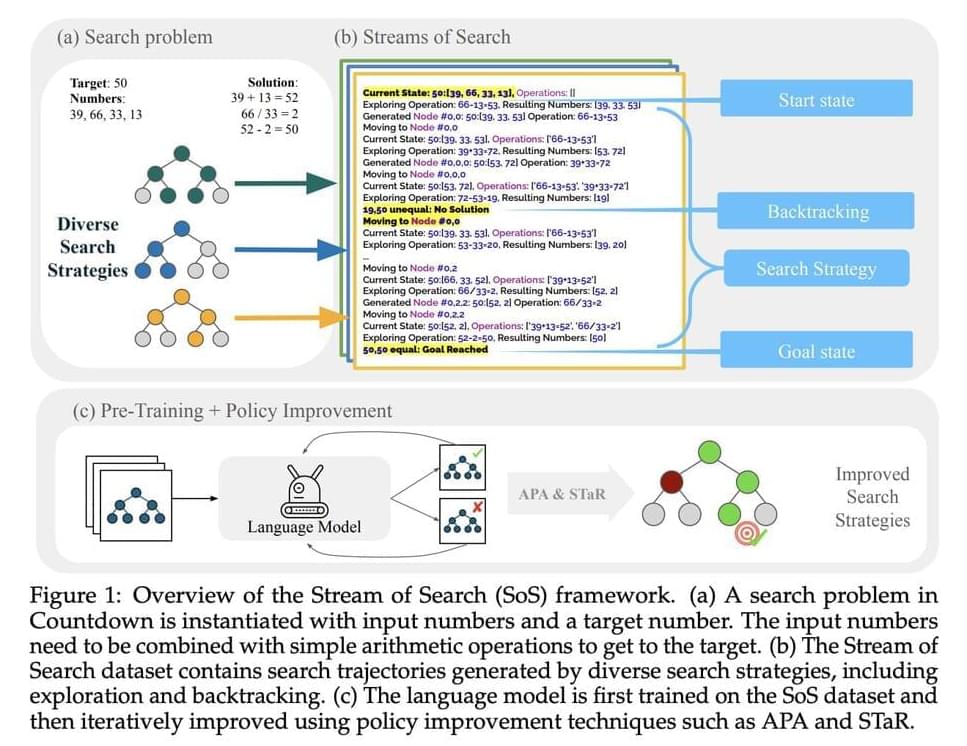
Researchers from Stanford University, MIT, and Harvey Mudd have devised a method to teach language models how to search and backtrack by representing the search process as a serialized string, Stream of Search (SoS). They proposed a unified language for search, demonstrated through the game of Countdown. Pretraining a transformer-based language model on streams of search increased accuracy by 25%, while further finetuning with policy improvement methods led to solving 36% of previously unsolved problems. This showcases that language models can learn to solve problems via search, self-improve, and discover new strategies autonomously.
Recent studies integrate language models into search and planning systems, employing them to generate and assess potential actions or states. These methods utilize symbolic search algorithms like BFS or DFS for exploration strategy. However, LMs primarily serve for inference, needing improved reasoning ability. Conversely, in-context demonstrations illustrate search procedures using language, enabling the LM to conduct tree searches accordingly. Yet, these methods are limited by the demonstrated procedures. Process supervision involves training an external verifier model to provide detailed feedback for LM training, outperforming outcome supervision but requiring extensive labeled data.