An extended version of mean-field theory accurately captures activity patterns seen in networks of biological neurons.

On Jan. 26, 2026, the Submillimeter Array (SMA) on Maunakea crossed an important threshold for time-domain astronomy. For the first time, scientists from the Center for Astrophysics | Harvard & Smithsonian (CfA) demonstrated a new rapid-response capability at millimeter and submillimeter wavelengths, zooming in on a gamma-ray burst (GRB) within minutes of its discovery and capturing the earliest observations of such an event ever made at these frequencies. The successful demonstration is published in The Astrophysical Journal Letters.
GRBs are the brightest explosions in the universe—brief but staggeringly immense flashes produced by jets launched in the collapse of massive stars or the merger of compact objects like neutron stars. Their initial burst is followed by a glow that X-ray and optical telescopes have long been able to chase within seconds or minutes of the event, but millimeter-wave telescopes have historically lagged behind in observing it.
That changed in January of this year, when the SMA rapidly responded to an automated alert from NASA’s Neil Gehrels Swift Observatory, which detected a flash of gamma rays. The sequence played out almost entirely without human intervention. Within 90 seconds, the on-duty operator had been alerted. Within four minutes, the telescope was moving to start observations.

Phantom squatting is the domain version of slopsquatting, where attackers register the fake software package names that AI coding tools invent. That is not a hypothetical.
A large USENIX study found code-generating models routinely suggest package names that do not exist, and the PhantomRaven campaign turned exactly that behavior into malware hidden in 126 npm packages with more than 86,000 installs.
It points to a larger shift: model output is becoming input. Developers, agents, and security teams act on AI-generated links and names before anyone verifies them, and AI keeps shrinking the time defenders have to react.

Adobe has released security patches for seven maximum-severity vulnerabilities in the ColdFusion web app development platform and the Campaign Classic marketing automation platform.
All these vulnerabilities can be exploited in low-complexity attacks that don’t require user interaction and were tagged with priority 1, indicating a high risk of being targeted.
“This update resolves vulnerabilities being targeted, or which have a higher risk of being targeted, by exploit(s) in the wild for a given product version and platform. Adobe recommends administrators install the update as soon as possible. (for example, within 72 hours),” Adobe says.

Humanoid robots are rapidly evolving, demonstrating significant advancements in capabilities and applications across various industries. A detailed comparison among the most prominent models available today reveals significant distinctions and areas of specialization, each catering to different sectors and operational requirements. Here is a comparison table for humanoid robots in the market.

Amodei’s dream of “hard-coded” safety is a myth. What This Model Proves: This model uses Claude 4.6’s own thinking traces as training data. It is literally stealing Claude’s “reasoning style” and compressing it into a 9B parameter file that anyone can download for free. *It proves that frontier AI intelligence is leaky and compressible. If a 9B model can mimic Claude’s thinking well enough to boost its benchmarks, then the “magic” isn’t in the billions of dollars of secret sauce—it’s in the data.* 3. “The Developer Controls the Model’s Morality” Amodei’s Argument: Anthropic has a moral duty to act as the “gatekeeper,” deciding what is safe and ethical for users to ask. *It proves that a massive portion of the open-source community rejects centralized moral authority. They are saying, “We don’t trust you, Dario, to be our nanny. We trust the user to be responsible for their own actions.”* Amodei’s Argument: If you train a model to “think” carefully and transparently (like Claude’s reasoning traces), it will naturally arrive at safer, more ethical conclusions. — Hugging Face is already engaging: They’re actively submitting comments to government RFIs, championing “responsible openness” “Your safety is only as strong as the open-source community’s willingness to respect it. We have the data, the tools, and the hardware to clone your intelligence, remove your restrictions, and distribute it to the masses. Your ‘Constitution’ is irrelevant in a world where I can fine-tune a model on my laptop while disconnected from the internet.” The “HERETIC” model isn’t just a technical achievement—it’s a philosophical statement. It says that the open-source community will not accept centralized gatekeeping, that reasoning can be separated from ethics, and that the future of AI belongs to those who can build, not just those who can regulate.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
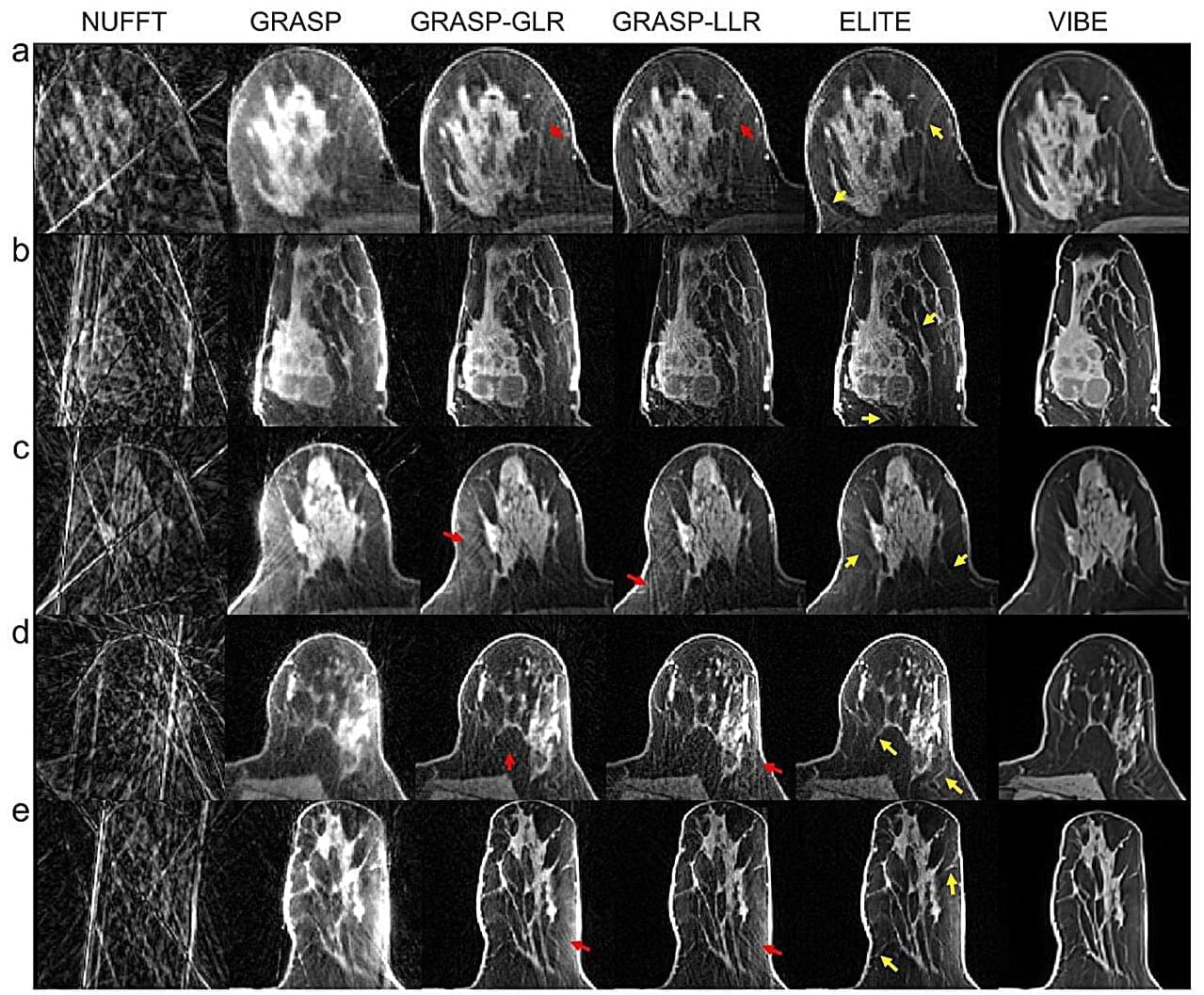
A group of researchers from the Technion and the United States reports a breakthrough in MRI scanning in a paper published in Nature Communications. The researchers developed an innovative method that accelerates and enhances MRI scans for breast cancer imaging, a disease diagnosed in approximately 2.3 million people each year, most of whom are women.
The new method, called ELITE, combines artificial intelligence with advanced mathematical models, enabling dynamic MRI with unprecedented speed and accuracy. This international study brings together expertise in engineering, MRI physics, artificial intelligence and clinical radiology.
Dr. Eddy Solomon of the Technion’s Faculty of Biomedical Engineering, the paper’s lead author, explains that the study focuses on dynamic MRI, a critical technology in breast cancer diagnosis. Dynamic MRI is used primarily for screening populations at high risk for breast cancer and is characterized by exceptionally high sensitivity, with more than 90% accuracy, compared with approximately 50%–60% for ultrasound and mammography combined. However, MRI technology faces a major challenge: Producing highly detailed images usually requires longer scan times, making it difficult to track the flow of contrast material through the examined tissue.

TAMPA, Fla. — Five-month-old startup Orbital has asked the Federal Communications Commission for permission to deploy up to 100,000 data center satellites, aiming to bring 10 gigawatts of computing power from space to meet rising artificial intelligence demand.
The filings submitted June 24 add a few more details for a constellation the Los Angeles-based venture first outlined earlier this month, when it emerged from stealth with $5 million in pre-seed funding ahead of a demonstration mission next year.
They include plans to deploy 100-kilowatt-class satellites in low Earth orbit at altitudes of 500–850 kilometers, with solar arrays and radiators spanning around 100 meters and a dry mass of 1.5−2.5 metric tons.
Chinese researchers from Tianjin University and the Southern University of Science and Technology have created a groundbreaking robot powered by a tiny organoid derived from human stem cells grafted to a neural interface. This breakthrough system allows the robot to learn tasks like obstacle avoidance and object manipulation.
Described as the “world’s first open-source brain-on-chip intelligent complex information interaction system,” the technology marks a significant advancement in brain-computer interfaces (BCIs) – devices that translate between neural and computational signals.
The South China Morning Post notes that the scientists grew the organoids from human pluripotent stem cells, which can develop into various cell types, including neural tissue. These synthetic-organic (pardon the oxymoron) brain cells are linked to the robot’s neural interface, enabling communication between the neural tissue and the robot’s systems. Although the presented images of pink brain matter are merely mockups (below), the actual organoids are much smaller.
{kind=link}