The methods currently used to correct systematic issues in NLP models are either fragile or time-consuming and prone to shortcuts. Humans, on the other hand, frequently reprimand one another using natural language. This inspired recent research on natural language patches, which are declarative statements that enable developers to deliver corrective feedback at the appropriate level of abstraction by either modifying the model or adding information the model may be missing.
Instead of relying solely on labeled examples, there is a growing body of research on using language to provide instructions, supervision, and even inductive biases to models, such as building neural representations from language descriptions (Andreas et al., 2018; Murty et al., 2020; Mu et al., 2020), or language-based zero-shot learning (Brown et al., 2020; Hanjie et al., 2022; Chen et al., 2021). For corrective purposes, when the user interacts with an existing model to enhance it, language has yet to be properly utilized.
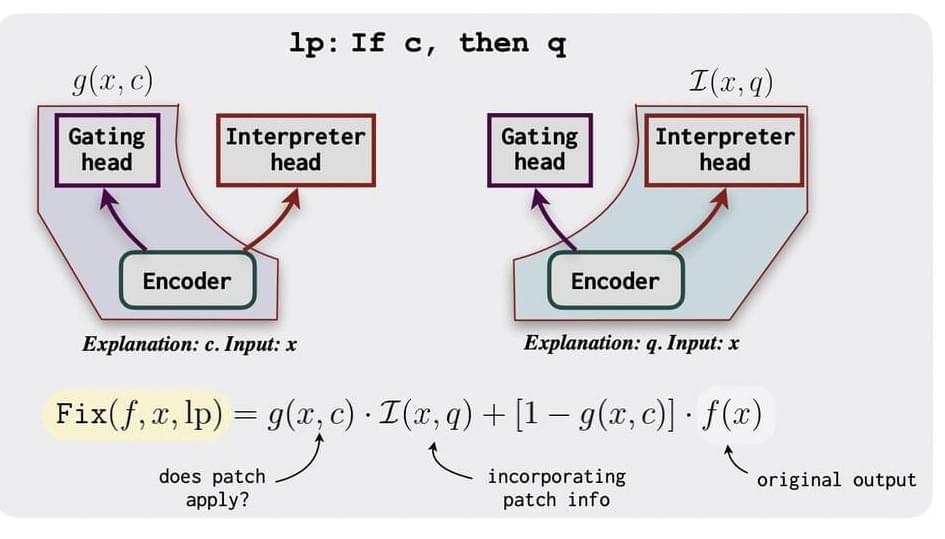
The neural language patching model has two heads: a gating head that determines if a patch should be applied and an interpreter head that forecasts results based on the information in the patch. The model is trained in two steps: first on a tagged dataset and then through task-specific fine-tuning. A set of patch templates are used to create patches and synthetic labeled samples during the second fine-tuning step.