The biggest benchmarking data set to date for a machine learning technique designed with data privacy in mind has been released open source by researchers at the University of Michigan.
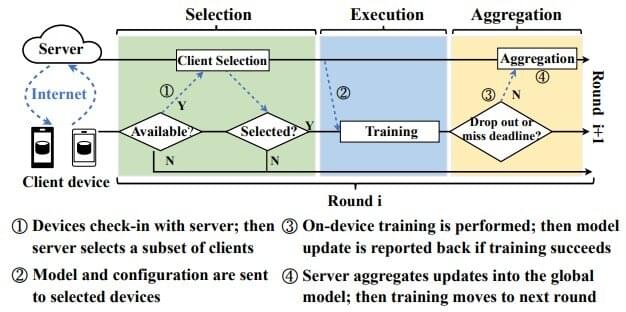
Called federated learning, the approach trains learning models on end-user devices, like smartphones and laptops, rather than requiring the transfer of private data to central servers.
“By training in-situ on data where it is generated, we can train on larger real-world data,” explained Fan Lai, U-M doctoral student in computer science and engineering, who presents the FedScale training environment at the International Conference on Machine Learning this week.