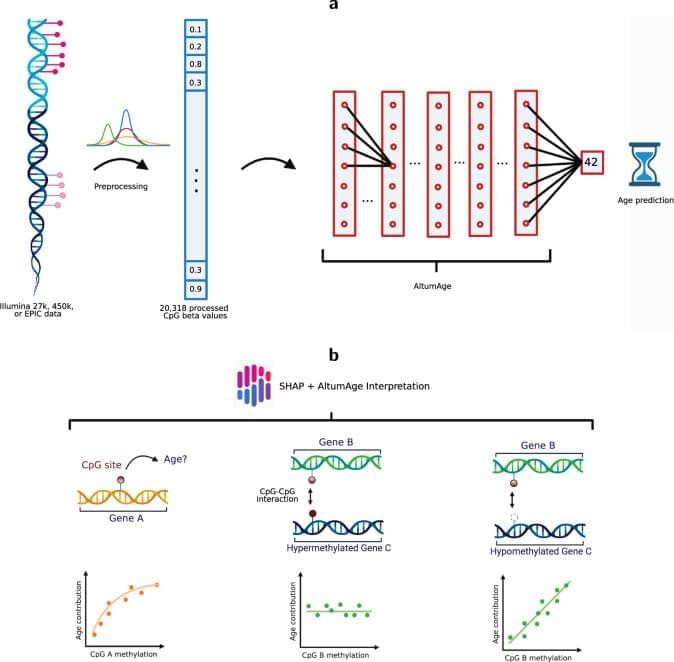
Next, we aimed to determine whether the model type, i.e., a linear regression vs. a neural network, would significantly impact the performance. We, therefore, compared the aforementioned linear models with the neural network AltumAge using the same set of features. AltumAge outperformed the respective linear model with Horvath’s 353 CpG sites (MAE = 2.425 vs. 3.011, MSE = 32.732 vs. 46.867) and ElasticNet-selected 903 CpG sites (MAE = 2.302 vs. 2.621, MSE = 30.455 vs. 39.198). This result shows that AltumAge outperforms linear models given the same training data and set of features.
Lastly, to compare the effect of the different sets of CpG sites, we trained AltumAge with all 20,318 CpG sites available and compared the results from the smaller sets of CpG sites obtained above. There is a gradual improvement in performance for AltumAge by expanding the feature set from Horvath’s 353 sites (MAE = 2.425, MSE = 32.732) to 903 ElasticNet-selected CpG sites (MAE = 2.302, MSE = 30.455) to all 20,318 CpG sites (MAE = 2.153, MSE = 29.486). This result suggests that the expanded feature set helps improve the performance, likely because relevant information in the epigenome is not entirely captured by the CpG sites selected by an ElasticNet model.
Overall, these results indicate that even though more data samples lower the prediction error, AltumAge’s performance improvement is greater than the increased data effect. Indeed, the lower error of AltumAge when compared to the ElaticNet is robust to other data splits (Alpaydin’s Combined 5x2cv F test p-value = 9.71e−5).