Apr 24, 2019
Synthetic speech generated from brain recordings
Posted by Mike Ruban in categories: biotech/medical, computing, neuroscience
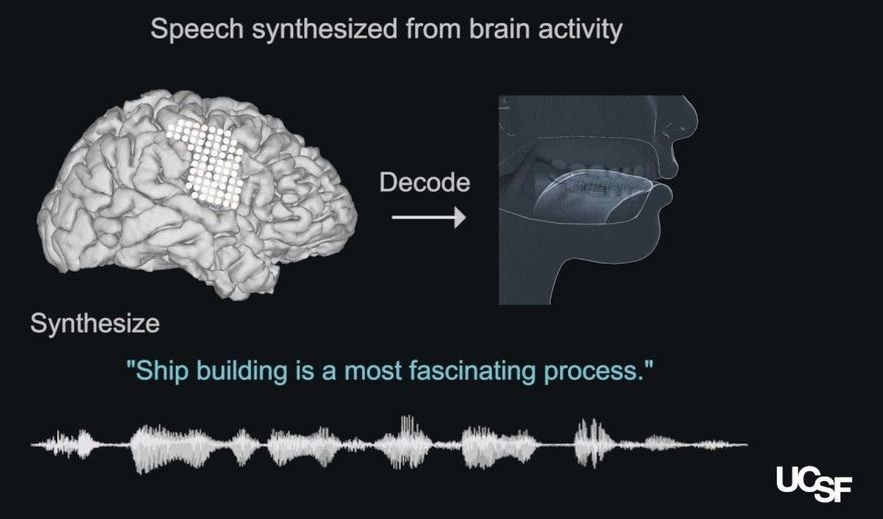
A state-of-the-art brain-machine interface created by UC San Francisco neuroscientists can generate natural-sounding synthetic speech by using brain activity to control a virtual vocal tract—an anatomically detailed computer simulation including the lips, jaw, tongue, and larynx. The study was conducted in research participants with intact speech, but the technology could one day restore the voices of people who have lost the ability to speak due to paralysis and other forms of neurological damage.
Stroke, traumatic brain injury, and neurodegenerative diseases such as Parkinson’s disease, multiple sclerosis, and amyotrophic lateral sclerosis (ALS, or Lou Gehrig’s disease) often result in an irreversible loss of the ability to speak. Some people with severe speech disabilities learn to spell out their thoughts letter-by-letter using assistive devices that track very small eye or facial muscle movements. However, producing text or synthesized speech with such devices is laborious, error-prone, and painfully slow, typically permitting a maximum of 10 words per minute, compared to the 100–150 words per minute of natural speech.
Continue reading “Synthetic speech generated from brain recordings” »