Year 2022 face_with_colon_three
Mental phenomena influence the material world.
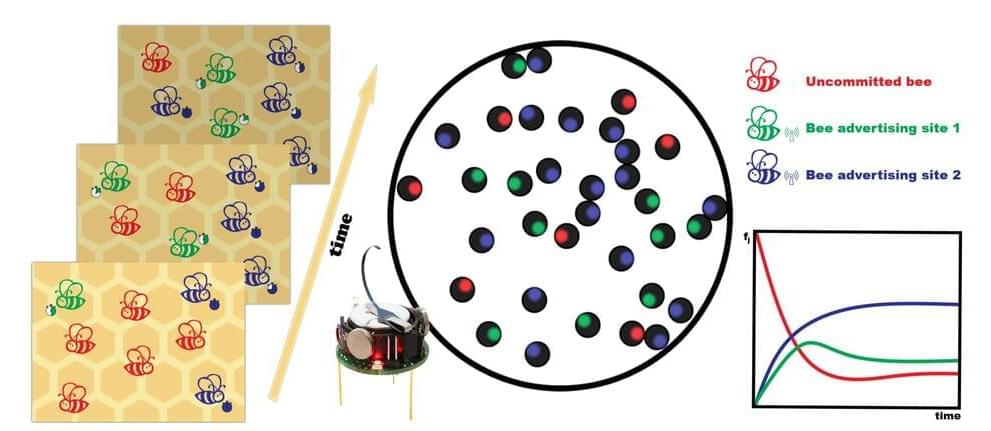
Researchers at the University of Barcelona have made a sweet discovery: Honeybees make great subjects when studying the dynamic of group behavior and decision-making.
In a recently released study, Professor M. Carmen Miguel, who has previously studied leadership activity among schooling fish and social interactions among flocks of birds, said a group of mini robots were trained to reach a consensus on tasks by mimicking processes displayed by bees.
The intricate behavior of bees has long been a subject of great interest among researchers. There are more than 4,000 species of the insect, and they have been around for more than 100 million years.

The human mind does not like to make mistakes—and makes time to avoid repeating them. A new study from University of Iowa researchers shows how the human brain, in just one second, can distinguish between an outcome caused by human error and one in which the person is not directly to blame.
Moreover, the researchers found that in cases of human error, the brain takes additional time to catalog the error and inform the rest of the body about it to avoid repeating the mistake.
“The novel aspect about this study is the brain can very quickly distinguish whether an undesirable outcome is due to a (human) error, or due to something else,” says Jan Wessel, professor in the Department of Psychological and Brain Sciences at Iowa and the study’s corresponding author. “If the brain realizes an error was the cause, it will then start additional processes to avoid further errors, which it won’t do if the outcome wasn’t due to its own action.”

Lasers are essential tools for observing, detecting, and measuring things in the natural world that we can’t see with the naked eye. But the ability to perform these tasks is often restricted by the need to use expensive and large instruments.
In a newly published cover-story paper in the journal Science, researcher Qiushi Guo demonstrates a novel approach for creating high-performance ultrafast lasers on nanophotonic chips. His work centers on miniaturizing mode-lock lasers—a unique laser that emits a train of ultrashort, coherent light pulses in femtosecond intervals, which is an astonishing quadrillionth of a second.
Ultrafast mode-locked lasers are indispensable to unlocking the secrets of the fastest timescales in nature, such as the making or breaking of molecular bonds during chemical reactions, or light propagation in a turbulent medium. The high-speed, pulse-peak intensity and broad-spectrum coverage of mode-locked lasers have also enabled numerous photonics technologies, including optical atomic clocks, biological imaging, and computers that use light to calculate and process data.

A recent study published in AGU Advances examines how the conservation and protection of two Alaskan forests, Tongass and Chugach, are essential in fighting the effects of climate change due to their expanse for wildlife habitats, abundant carbon stocks, and landscape integrity. This study was led by researchers from Oregon State University and holds the potential to help scientists better understand the steps that need to be taken to mitigate the long-term effects of climate change by preserving the resources of today.
Tongass National Forest (Credit: Logan Berner)
“More thoroughly safeguarding those forests from industrial development would contribute significantly to climate change mitigation and species adaptation in the face of the severe ecological disruption that’s expected to occur over the next few decades as the climate rapidly gets warmer,” said Dr. Beverly Law, who is a Professor Emeritus of Global Change Biology & Terrestrial Systems Science at Oregon State University and lead author of the study.

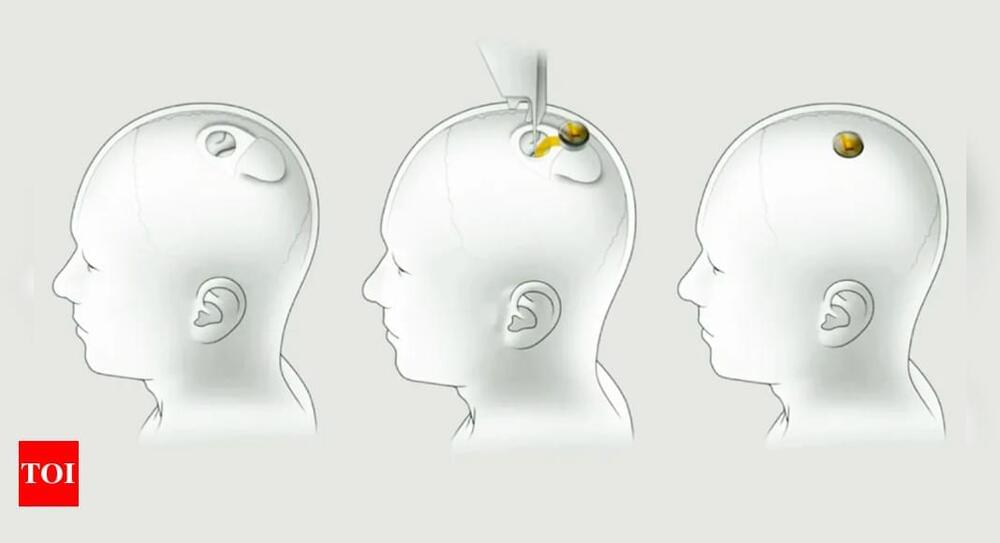
Elon Musk’s Neuralink is looking for a volunteer for its first clinical trial of a brain implant chip. The trial, which begins next year, has attracted thousands of prospective patients. The ideal candidate must be an adult under 40 with all four limbs paralyzed. The procedure involves inserting electrodes and wires into the brain, with a small computer replacing part of the skull. The computer will collect and analyze brain activity, sending the data wirelessly to a nearby device. Neuralink aims to translate thoughts into computer commands. However, the company has faced criticism for animal testing practices.

VentureBeat presents: AI Unleashed — An exclusive executive event for enterprise data leaders. Hear from top industry leaders on Nov 15. Reserve your free pass
MIT scientists have developed a deep learning system, Air-Guardian, designed to work in tandem with airplane pilots to enhance flight safety. This artificial intelligence (AI) copilot can detect when a human pilot overlooks a critical situation and intervene to prevent potential incidents.
The backbone of Air-Guardian is a novel deep learning system known as Liquid Neural Networks (LNN), developed by the MIT Computer Science and Artificial Intelligence Lab (CSAIL). LNNs have already demonstrated their effectiveness in various fields. Their potential impact is significant, particularly in areas that require compute-efficient and explainable AI systems, where they might be a viable alternative to current popular deep learning models.

Previous attempts at trapping them in 2D had failed.
Successful electron trapping in 3D
The MIT team looked for materials that could be used to work out 3D lattices in kagome patterns and came across pyrochlore — a mineral with highly symmetric atomic arrangements. In 3D, pyrochlore’s atoms formed a repeating pattern consisting of cubes in a kagome-like lattice.
To test their hypothesis, the team synthesized the pyrochlore using calcium and nickel. After heating the ingredients to very high temperatures, the mix was cooled, and the atoms arranged themselves into a kagome-like structure.