We then tested the new algorithms, called DQN with Proximal updates (or DQN Pro) and Rainbow Pro on a standard set of 55 Atari games. We can see from the graph of the results that the Pro agents overperform their counterparts; the basic DQN agent is able to obtain human-level performance after 120 million interactions with the environment (frames); and Rainbow Pro achieves a 40% relative improvement over the original Rainbow agent.
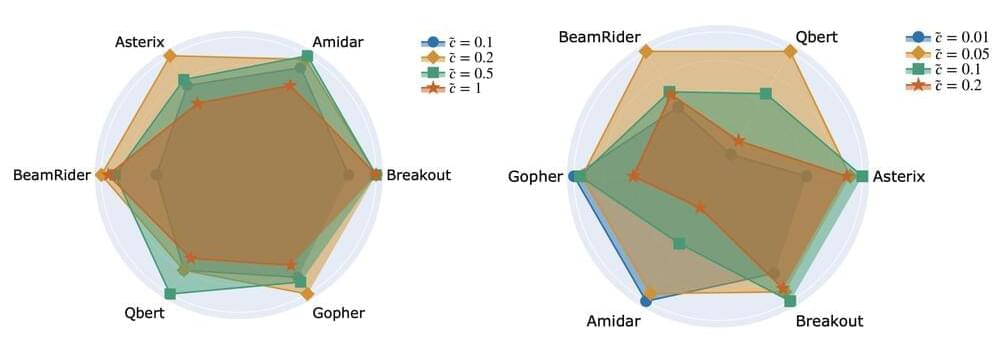
Further, to ensure that proximal updates do in fact result in smoother and slower parameter changes, we measure the norm differences between consecutive DQN solutions. We expect the magnitude of our updates to be smaller when using proximal updates. In the graphs below, we confirm this expectation on the four different Atari games tested.
Overall, our empirical and theoretical results support the claim that when optimizing for a new solution in deep RL, it is beneficial for the optimizer to gravitate toward the previous solution. More importantly, we see that simple improvements in deep-RL optimization can lead to significant positive gains in the agent’s performance. We take this as evidence that further exploration of optimization algorithms in deep RL would be fruitful.