Latent diffusion models (LDMs), a subclass of denoising diffusion models, have recently acquired prominence because they make generating images with high fidelity, diversity, and resolution possible. These models enable fine-grained control of the image production process at inference time (e.g., by utilizing text prompts) when combined with a conditioning mechanism. Large, multi-modal datasets like LAION5B, which contain billions of real image-text pairs, are frequently used to train such models. Given the proper pre-training, LDMs can be used for many downstream activities and are sometimes referred to as foundation models (FM).
LDMs can be deployed to end users more easily because their denoising process operates in a relatively low-dimensional latent space and requires only modest hardware resources. As a result of these models’ exceptional generating capabilities, high-fidelity synthetic datasets can be produced and added to conventional supervised machine learning pipelines in situations where training data is scarce. This offers a potential solution to the shortage of carefully curated, highly annotated medical imaging datasets. Such datasets require disciplined preparation and considerable work from skilled medical professionals who can decipher minor but semantically significant visual elements.
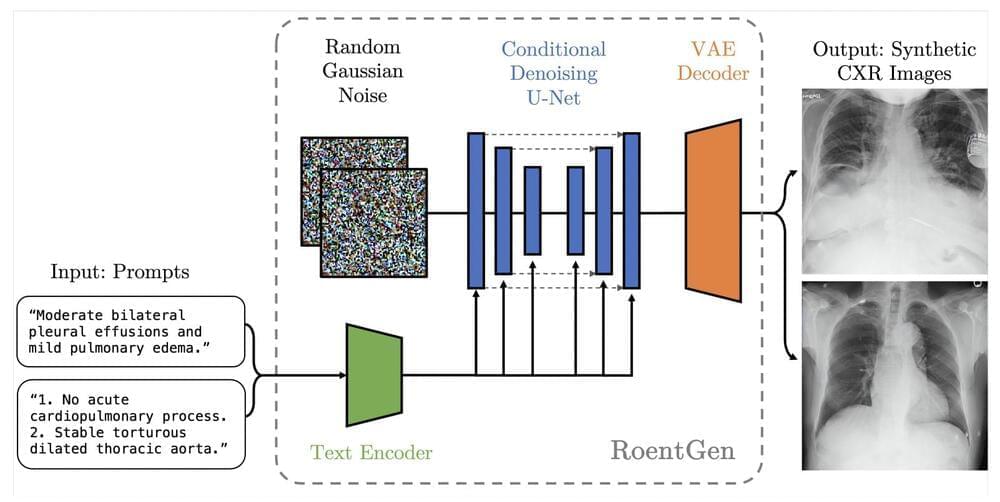
Despite the shortage of sizable, carefully maintained, publicly accessible medical imaging datasets, a text-based radiology report often thoroughly explains the pertinent medical data contained in the imaging tests. This “byproduct” of medical decision-making can be used to extract labels that can be used for downstream activities automatically. However, it still demands a more limited problem formulation than might otherwise be possible to describe in natural human language. By prompting pertinent medical terms or concepts of interest, pre-trained text conditional LDMs could be used to synthesize synthetic medical imaging data intuitively.