A Nature special on how AI is transforming the scientific enterprise.
Regenerative medicine might just have had a new tool added to its arsenal: Scientists have created tiny biological robots out of living human cells. Though they may be small, the self-assembling bots are mighty, with a study demonstrating their potential for healing and treating disease.
The team had already proven their biological robotics chops back in 2020 with the creation of Xenobots, made from frog embryonic cells. They even managed to design Xenobots so that they could reproduce in a way that no living animal or plant does, something that had never been seen before.
The researchers weren’t sure whether the incredible capabilities of the Xenobots were in some way down to their amphibious origins, so they wanted to find out if biobots could also be created from the cells of other organisms. And why not begin with humans?

A recent study published in IEEE Transactions on Control of Network Systems discusses how artificial intelligence (AI) can be used to control microgrids in the event of a long-term power outage caused by natural disasters or human error. This study was conducted by a team of researchers at UC Santa Cruz and holds the potential to improve power restoration techniques, which are traditionally controlled by local utility companies. One benefit of microgrids is they can function to power a small area, such as a town, until the primary utility source comes back online.
“Nowadays, microgrids are really the thing that both people in industry and in academia are focusing on for the future power distribution systems,” said Dr. Yu Zhang, who is an assistant professor of electrical and computer engineering at UC Santa Cruz and co-author on the study.
For the study, the researchers used an AI-based approach to develop a novel method where microgrids could draw power from renewable energy sources while being disconnected from the primary utility source, known as “islanding mode”, but can also function while being connected to the source, as well. This new method, which they refer to as constrained policy optimization (CPO), uses a machine learning algorithm that learns from outside input, such as real-time changes in environmental or power conditions, and makes the best-informed decisions on what to do next.

“People come from around the state and around the world to dive the Channel Islands, drawn by playful sea lions, underwater cathedrals of emerald kelp forests and giant sea bass weighing four times more than the divers themselves,” said Molly Morse.
Can marine protected areas (MPAs) have a positive effect on the scuba diving industry? This is something a recent study published in Marine Policy hopes to find out as a team of researchers led by the University of California, Santa Barbara (UCSB) highlighted the potential benefits that MPAs could have on ecotourism in California’s Channel Islands, specifically for scuba divers.
For the study, the researchers used data collected between 2016 and 2022 from an onboard vessel location system known as Automatic Identification System (AIS)—which boat captains use during scuba diving tours—and interviewed for-hire vessel captains with the goal of ascertaining the location of these ecotours with respect to MPAs and their corresponding borders of protection. In the end, the team found that the ecotours vessels favored MPAs for their activities, specifically for lobster fishing and scuba diving, and that 38 percent of the most popular ecotourism diving locations were within MPAs, with 45 percent of diving activities occurring within MPAs, as well.



Physicists are coming to realise that hypothetical particles called axions could explain not only dark matter, but dark energy too, and more besides. Now there is fresh impetus to detect them.
Meta AI researchers announced on Thursday that they have developed a new suite of artificial intelligence models called Seamless Communication that aim to enable more natural and authentic communication across languages — essentially making the concept of a Universal Speech Translator a reality. The models were publicly released this week along with research papers and accompanying data.
The flagship model, called Seamless, merges capabilities from three other models — SeamlessExpressive, SeamlessStreaming, and SeamlessM4T v2 — into one unified system. According to the research paper, Seamless is “the first publicly available system that unlocks expressive cross-lingual communication in real-time.”
The Seamless translator represents a new frontier in the use of AI for communication across the blog. It combines three sophisticated neural network models to enable real-time translation between over 100 spoken and written languages while preserving the vocal style, emotion, and prosody of the speaker’s voice.

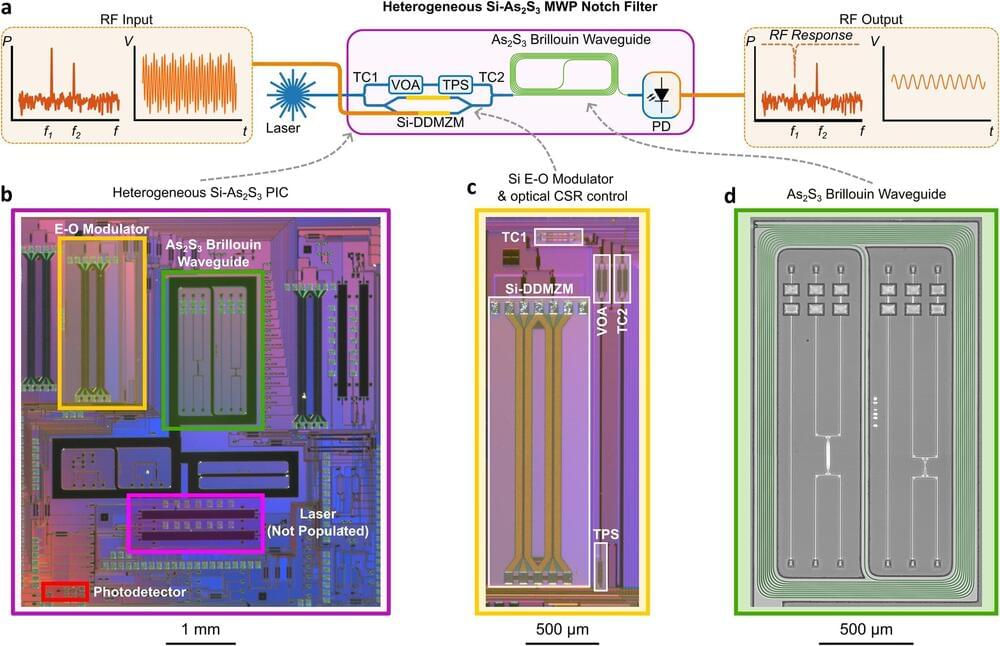
Researchers at the University of Sydney Nano Institute have invented a compact silicon semiconductor chip that integrates electronics with photonic, or light, components. The new technology significantly expands radio-frequency (RF) bandwidth and the ability to accurately control information flowing through the unit.
Expanded bandwidth means more information can flow through the chip and the inclusion of photonics allows for advanced filter controls, creating a versatile new semiconductor device.
Researchers expect the chip will have applications in advanced radar, satellite systems, wireless networks and the roll-out of 6G and 7G telecommunications and also open the door to advanced sovereign manufacturing. It could also assist in the creation of high-tech value-add factories at places like Western Sydney’s Aerotropolis precinct.
{kind=link}
{kind=link}