Hackathons using AlphaGenome and other AI models are hunting down the genetic causes of devastating conditions that have evaded diagnosis.


New technology from University of Houston researchers could improve the way devices manage heat, thanks to a technique that allows heat to flow in only one direction. The innovation is known as thermal rectification, and was developed by Bo Zhao, an award-winning and internationally recognized engineering professor at the Cullen College of Engineering, and his doctoral student Sina Jafari Ghalekohneh. The work is published in Physical Review Research.
A new way to steer heat
This new technology gives engineers a new way to control radiative heat with the same precision that electronic diodes control electrical currents, which means longer-lasting batteries for cell phones, electric vehicles and even satellites. It also has the potential to change our approach to AI data centers.
Cancer patients who suffer a heart attack face a dangerous mix of risks, which makes their clinical treatment particularly challenging. As a result, patients with cancer have been systematically excluded from many clinical trials and available risk scores. Until now, doctors had no standard tool to guide treatment in this vulnerable group.
An international team led by researchers from the University of Zurich (UZH) has now developed the first risk prediction model designed specifically for cancer patients who have had a heart attack. The study, published in The Lancet, analyzed more than one million heart attack patients in England, Sweden and Switzerland, including over 47,000 with cancer.
Overall, the results show that cancer patients have a strikingly poor prognosis: nearly one in three died within six months, while around one in 14 suffered a major bleed and one in six experienced another heart attack, stroke or cardiovascular death.


Each year, thousands of professionals contribute to GDC’s State of the Game Industry report, offering studios, investors, and creators a snapshot of where the market is headed.
This year’s survey gathered responses from more than 2,300 game industry professionals, including developers, producers, marketers, executives, and investors, covering topics such as layoffs, diversity and inclusion, business models, and generative AI. Just over half of respondents were based in the United States, with a disproportionate share coming from North America and Western Europe, meaning the survey is not fully representative of the global industry.
However, some of these findings may reflect broader global trends. You can feel the mood shifting around AI, with its use increasingly sparking backlash whenever it comes up, from Baldur’s Gate 3 controversies to “Microslop”.

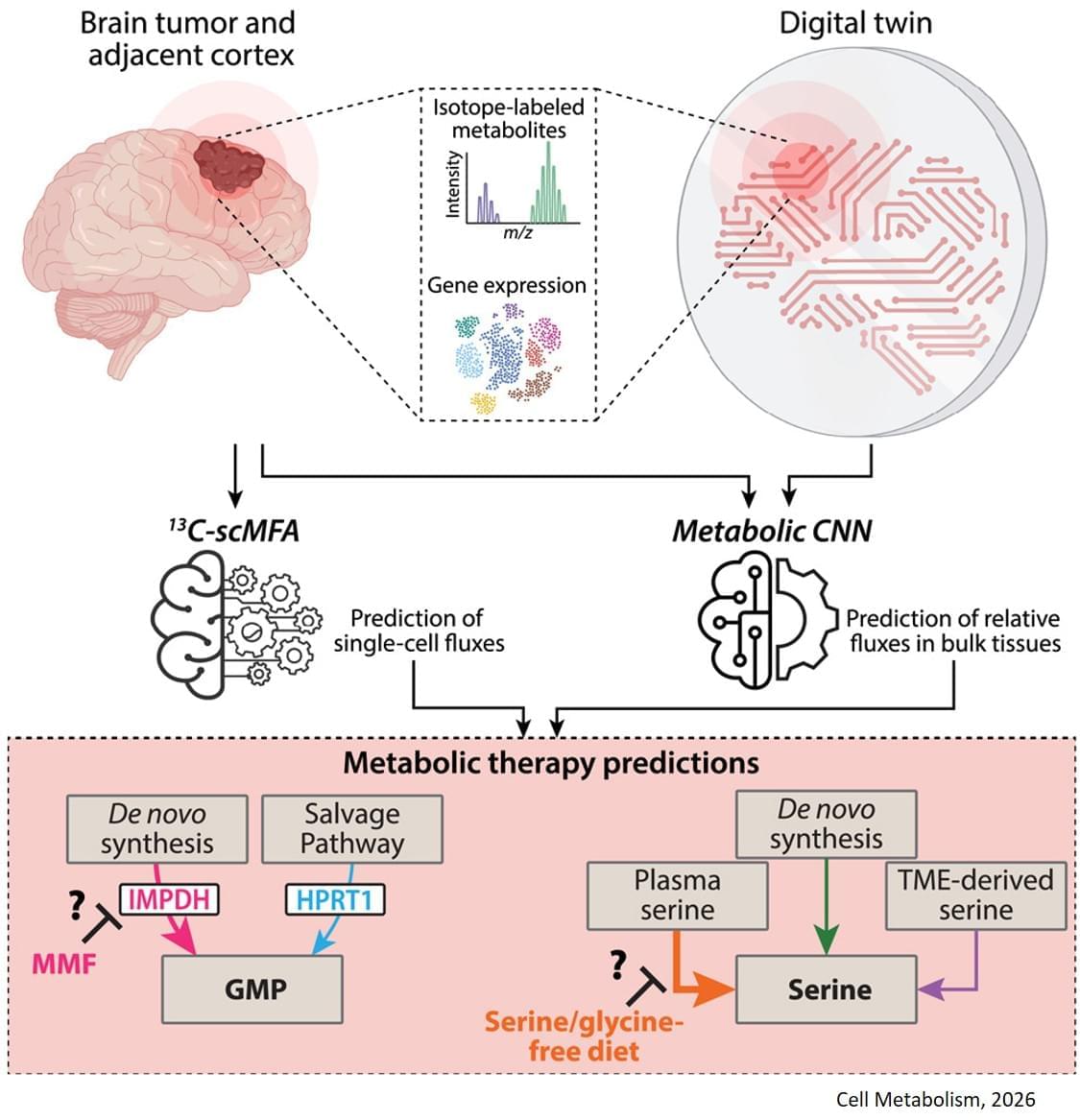
The study, published in Cell Metabolism, builds on previous research showing that some gliomas can be slowed down through the patient’s diet. If a patient isn’t consuming certain protein building blocks, called amino acids, then some tumors are unable to grow. However, other tumors can produce these amino acids for themselves, and can continue growing anyway. Until now, there was no easy way to tell which patients would benefit from dietary restrictions.
The digital twin’s ability to map metabolic activity in tumors also helped determine whether a drug that prevents tumors from producing a building block for replicating and repairing DNA would work, as some cells can obtain that molecule from their environments.
To overcome challenges in mapping tumor metabolism inside the brain, the team developed a computer-based “digital twin” that can predict how an individual patient’s brain tumor will react to each treatment.
“Typically, metabolic measurements during surgeries to remove tumors can’t provide a clear picture of tumor metabolism—surgeons can’t observe how metabolism varies with time, and labs are limited to studying tissues after surgery. By integrating limited patient data into a model based on fundamental biology, chemistry and physics, we overcame these obstacles,” said a co-corresponding author of the study.
The digital twin uses patient data obtained through blood draws, metabolic measurements of the tumor tissue and the tumor’s genetic profile. The digital twin then calculates the speed at which the cancer cells consume and process nutrients, known as metabolic flux.
“This is the first time a machine learning and AI-based approach has been used to measure metabolic flux directly in patient tumors,” said a co-first author of the study.
The researchers built a type of deep learning model called a convolutional neural network and trained it on synthetic patient data, generated based on known biology and chemistry and constrained by measurements from eight patients with glioma who were infused with labeled glucose during surgery. By comparing their computer models with different data from six of those patients, they found the digital twins could predict metabolic activity with high accuracy. In experiments conducted on mice, the team confirmed that the diet only slowed tumor growth in mice that the digital twin had identified as good candidates for the treatment.



As of January 2026, the global race for semiconductor supremacy has reached a fever pitch, centered on a massive, truck-sized machine that costs more than a fleet of private jets. ASML (NASDAQ: ASML) has officially transitioned its “High-NA” (High Numerical Aperture) Extreme Ultraviolet (EUV) lithography systems into high-volume manufacturing, marking the most significant shift in silicon fabrication in over a decade. While the industry grapples with the staggering $350 million to $400 million price tag per unit, Intel (NASDAQ: INTC) has emerged as the aggressive vanguard, betting its entire “IDM 2.0” turnaround strategy on being the first to operationalize these tools for the next generation of “Angstrom-class” processors.
The transition to High-NA EUV is not merely a technical upgrade; it is a fundamental reconfiguration of how the world’s most advanced AI chips are built. By enabling higher-resolution circuitry, these machines allow for the creation of transistors so small they are measured in Angstroms (tenths of a nanometer). For an industry currently hitting the physical limits of traditional EUV, this development is the “make or break” moment for the continuation of Moore’s Law and the sustained growth of generative AI compute.