A drop of dye added to a glass of water undergoes ordinary diffusion. However, when placed on the surface of a foam, the dye spreads differently—diffusion becomes anomalous. An example of this is the pattern on the froth of a cup of cappuccino. Interestingly, recent research suggests that diffusion equations in a heterogeneous environment can also describe social phenomena, such as election results or the behavior of stock market traders. The study is published in the Chaos: An Interdisciplinary Journal of Nonlinear Science.
The movement of particles in complex media—such as porous materials, gels or foams—bears more resemblance to a random journey through an irregular maze than to a leisurely stroll through a homogeneous space. The presence of local “traps” alongside narrow passages or branches causes the transport of matter or energy to be significantly slowed down or accelerated. Such deviations from classical diffusion are referred to as anomalous diffusion. It is also observed in media with a nonuniform structure.
An international team of physicists from Poland, Croatia, Macedonia and Hungary has undertaken a mathematical description of diffusion in such systems; the Polish side was represented by scientists from the Institute of Nuclear Physics of the Polish Academy of Sciences (IFJ PAN) in Cracow.
New mathematical research suggests dark energy may not be needed to explain the accelerating expansion of the universe, challenging the foundations of the standard cosmological model.
A 90 minute interview about AI and our human future.
Dr. Hugo de Garis is a computer scientist, AI researcher, and former professor known for his early work on evolvable hardware, artificial brains, and the long-term risks of superintelligent machines. He coined and popularized the idea of the “Artilect War,” a future conflict between those who want to build godlike artificial intellects and those who believe such systems pose an existential threat to humanity. In the interview, he describes himself as trained in pure mathematics and theoretical physics, formerly a computer science professor, and now focused on broader questions about AI, cosmology, civilization, and the future of humanity.
The interview with Prof. Hugo de Garis centers on his long-standing warning that humanity may face an “Artilect War,” a civilizational conflict over whether to build godlike artificial intellects vastly superior to humans. De Garis argues that future computation, potentially extending from nanotech to femtotech and beyond, could produce minds trillions of trillions of times more capable than ours. He distinguishes between Cosmists, who want to build such beings to expand intelligence into the universe, and Terrans, who oppose them because superintelligence may eliminate or marginalize humanity. He personally remains torn, admiring the cosmic grandeur of posthuman intelligence while recognizing the existential danger.
The conversation also covers AI timelines, recursive self-improvement, AI alignment, the U.S.-China race, the Fermi paradox, simulation theory, cyborgs, cryonics, AI-generated content, the decline of universities, and the future of work. De Garis is impressed by current AI systems, treating them almost as intellectual companions, but he doubts that humanity can guarantee long-term control over recursively improving machines. The central theme is that the question “Should humanity build artilects?” may become the defining political and moral problem of the twenty-first century.
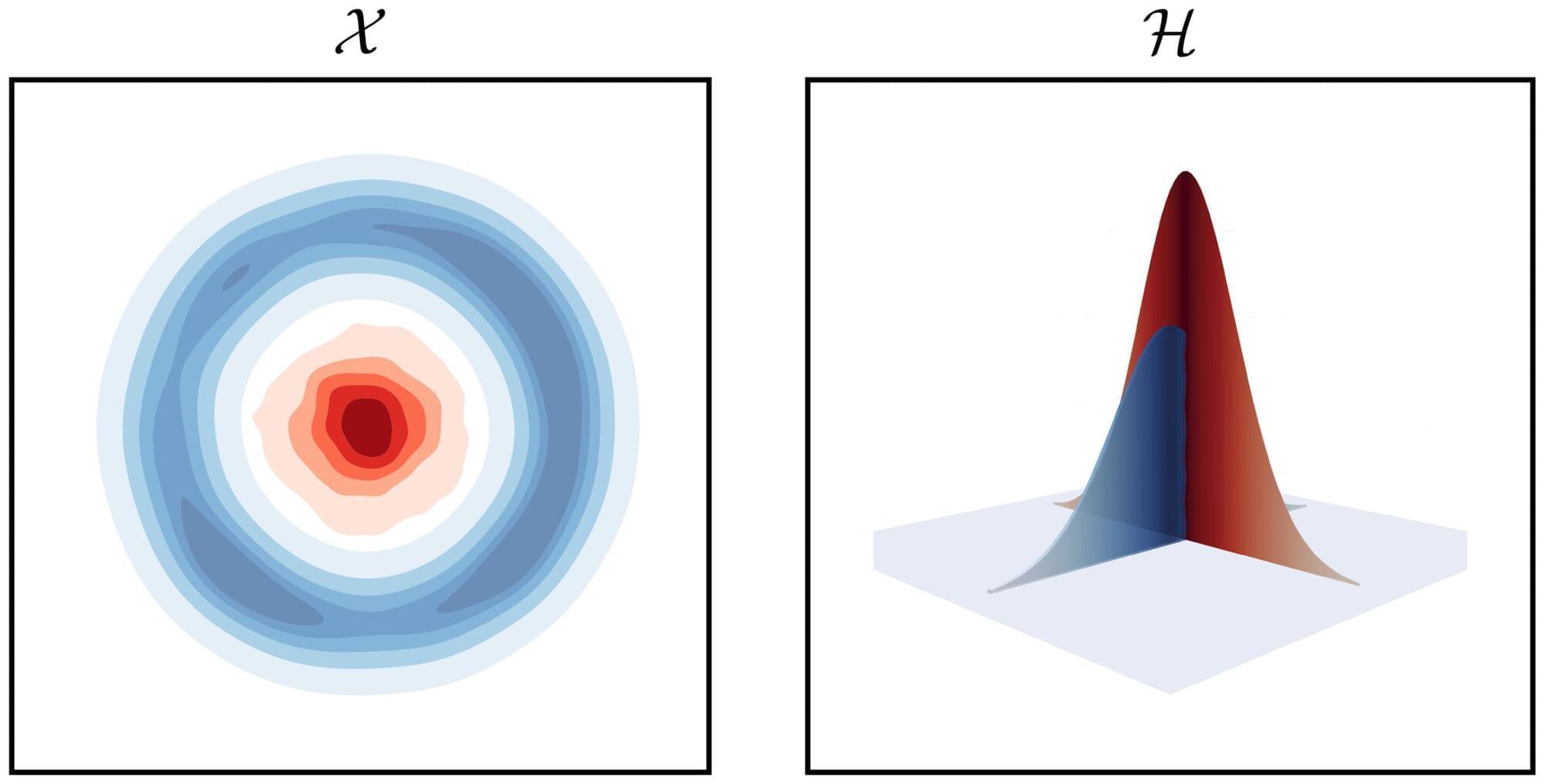
Are two sets of data genuinely different, or is it because of randomness? This question, known as the two-sample testing problem, becomes notoriously difficult in modern datasets, because they are often high-dimensional, complex, and differences between them can take countless subtle forms.
“Simply put, we don’t know what differences to look for, the possibilities are bewildering,” says Professor Victor Panaretos at EPFL’s Institute of Mathematics.
To solve the problem, mathematicians have developed the so-called “kernel methods,” which have emerged as powerful solutions, widely used in fields such as genomics, finance, and artificial intelligence.
Gravitational waves are tiny ripples in spacetime. Their first direct detection in 2015 marked a revolutionary moment in astronomy. Today, we have a thorough understanding of signals that travel far from their sources through quiet, nearly empty space, such as those emitted when black holes merge. In this case, the wave can be considered a minor disturbance on a silent background. The distinction between “background” and “wave” is clear, and the quantity measured by the detector—a tiny stretching and squeezing—is clearly determined.
In cosmology, however, things are more subtle. The focus shifts to the universe in its entirety—encompassing spacetime and everything contained within it, such as stars, black holes and galaxies. The background itself is dynamic. Small fluctuations in density and velocity gently stir spacetime everywhere, blurring the boundary with the wave.
But what exactly does a gravitational-wave detector measure when the entire universe is gently vibrating? Previously, theoretical predictions were entirely dependent on the choice of mathematical coordinates. However, the only meaningful quantity is what a real instrument records, which must be coordinate-independent.
Is the random motion of particles suspended in a medium (a liquid or a gas). [ 2 ] The traditional mathematical formulation of Brownian motion is that of the Wiener process, which is often itself called “Brownian motion”, even in mathematical sources.
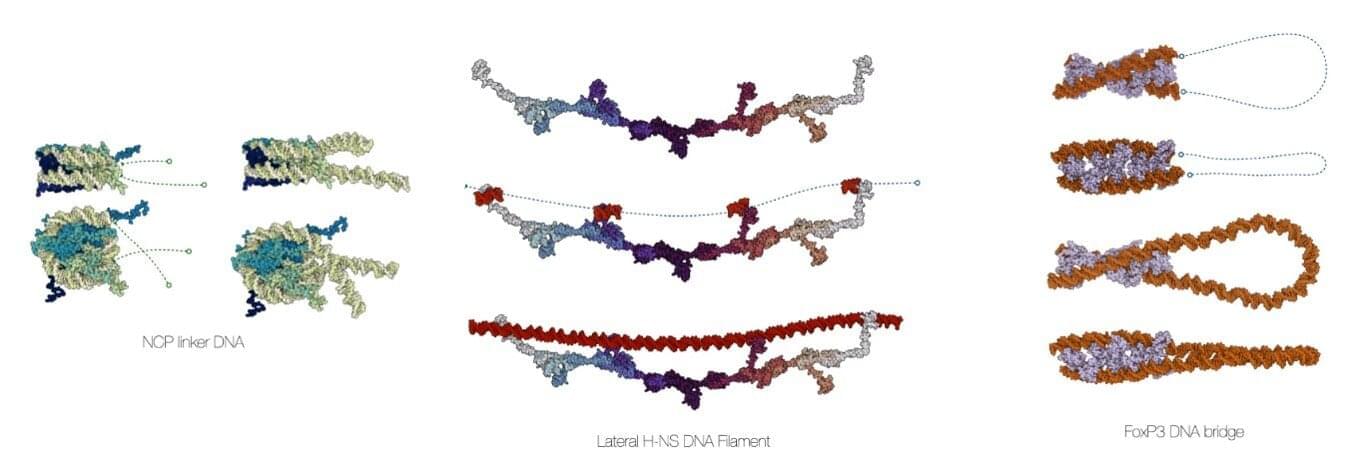
Computational chemists at the University of Amsterdam’s Van ‘t Hoff Institute for Molecular Sciences have developed a comprehensive software suite to create accurate models of DNA in biomolecular assemblies. Called MDNA, the user-friendly molecular modeling toolkit helps biochemists, molecular biologists, bioinformaticians, and biophysicists to visualize and analyze DNA structures and perform accurate simulations.
The development of the MDNA suite, led by associate professor Jocelyne Vreede, has been presented in a paper in Nucleic Acids Research.
The software is open-source and publicly available through Figshare and Github. It is easily accessible, providing inspiration to any scientist with an interest in DNA. It has been thoroughly tested by students in mathematics, chemistry and biology, some of whom had hardly any programming experience.