Recorded 10 February 2026. Sebastien Bubeck of OpenAI presents “A Combinatorics Problem” at IPAM’s AI for Science Kickoff. Learn more online at: https://www.ipam.ucla.edu/programs/sp… AI for Science Kickoff 2026: This inaugural event brings together the pioneers who are defining how AI will accelerate scientific discovery — from Nobel and Fields Medal laureates to the leaders shaping AI innovation across academia, research labs, and industry. The event features keynote talks by leading AI Scientists and Mathematicians, as well as panel discussions focusing on perspectives on AI from three sides: Mathematics, Higher Education, and Industry. This event is organized jointly by IPAM, the UCLA Division of Physical Sciences, the SAIR Foundation and the World Leading Scientists Institute.
Category: mathematics – Page 2

Brain inspired machines are better at math than expected
Neuromorphic computers modeled after the human brain can now solve the complex equations behind physics simulations — something once thought possible only with energy-hungry supercomputers. The breakthrough could lead to powerful, low-energy supercomputers while revealing new secrets about how our brains process information.
Alien Mathematics
Aliens will make use of paraconsistent logic.
Is math truly universal—or just human? Explore how alien minds might think, count, and reason in ways we don’t recognize as mathematics at all.
Get Nebula using my link for 50% off an annual subscription: https://go.nebula.tv/isaacarthur.
Watch my exclusive video The Future of Interstellar Communication: https://nebula.tv/videos/isaacarthur–… out Joe Scott’s Oldest & Newest: https://nebula.tv/videos/joescott-old… 🚀 Join this channel to get access to perks: / @isaacarthursfia 🛒 SFIA Merchandise: https://isaac-arthur-shop.fourthwall… 🌐 Visit our Website: http://www.isaacarthur.net 🎬 Join Nebula: https://go.nebula.tv/isaacarthur ❤️ Support us on Patreon:
/ isaacarthur ⭐ Support us on Subscribestar: https://www.subscribestar.com/isaac-a… 👥 Facebook Group:
/ 1,583,992,725,237,264 📣 Reddit Community:
/ isaacarthur 🐦 Follow on Twitter / X:
/ isaac_a_arthur 💬 SFIA Discord Server:
/ discord Credits: Alien Mathematics Written, Produced & Narrated by: Isaac Arthur Select imagery/video supplied by Getty Images Music by Epidemic Sound: http://nebula.tv/epidemic & Stellardrone Chapters 0:00 Intro 2:02 Why We Expect Mathematics to Be Universal 6:32 Math Is Not the Same Even for Humans 10:47 How Alien Biology Could Reshape Their Mathematics 16:44 Alien Logic: When the Rules Themselves Don’t Match 20:37 Oldest & Newest 21:41 Can We Ever Bridge the Mathematical Gap?
Check out Joe Scott’s Oldest & Newest: https://nebula.tv/videos/joescott-old…
🚀 Join this channel to get access to perks: / @isaacarthursfia.
🛒 SFIA Merchandise: https://isaac-arthur-shop.fourthwall…
🌐 Visit our Website: http://www.isaacarthur.net.
🎬 Join Nebula: https://go.nebula.tv/isaacarthur.
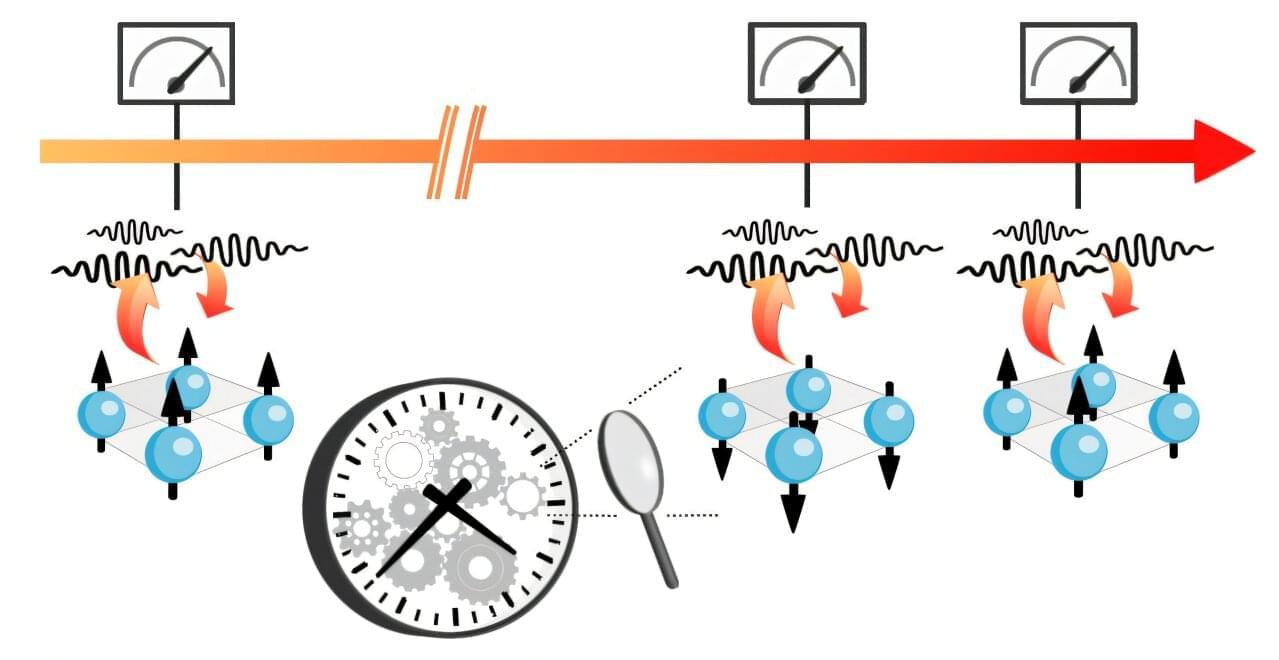
Time crystals could become accurate and efficient timekeepers
Time crystals could one day provide a reliable foundation for ultra-precise quantum clocks, new mathematical analysis has revealed. Published in Physical Review Letters, the research was led by Ludmila Viotti at the Abdus Salam International Center for Theoretical Physics in Italy. The team shows that these exotic systems could, in principle, offer higher timekeeping precision than more conventional designs, which rely on external excitations to generate reliably repeating oscillations.
In physics, a crystal can be defined as any system that hosts a repeating pattern in its microscopic structure. In conventional crystals, this pattern repeats in space—but more exotic behavior can emerge in materials whose configurations repeat over time. Known as “time crystals,” these systems were first demonstrated experimentally in 2016. Since then, researchers have been working to understand the full extent of their possible applications.

Graham Priest: Dialetheism & the Limits of Classical Logic
For 2,500 years, Western thought has treated contradiction as catastrophic.
From Aristotle’s law of non-contradiction to modern formal systems, logic has operated under one sacred assumption: a statement cannot be both true and false.
But what if that assumption is wrong?
In my latest Singularity. FM conversation, I sit down with Graham Priest — one of the world’s leading philosophers of logic and the foremost defender of *dialetheism* — the view that some contradictions are true.
We explore:
• Why the liar paradox still unsettles logicians • How paraconsistent logic blocks “explosion” • Whether classical logic is incomplete rather than universal • What Buddhist philosophy understood about contradiction centuries ago • And whether AI systems may require non-classical logics to model human reasoning.
The Frontier Labs War: Opus 4.6, GPT 5.3 Codex, and the SuperBowl Ads Debacle
Questions to inspire discussion AI Model Performance & Capabilities.
🤖 Q: How does Anthropic’s Opus 4.6 compare to GPT-5.2 in performance?
A: Opus 4.6 outperforms GPT-5.2 by 144 ELO points while handling 1M tokens, and is now in production with recursive self-improvement capabilities that allow it to rewrite its entire tech stack.
🔧 Q: What real-world task demonstrates Opus 4.6’s agent swarm capabilities?
A: An agent swarm created a C compiler in Rust for multiple architectures in weeks for **$20K, a task that would take humans decades, demonstrating AI’s ability to collapse timelines and costs.
🐛 Q: How effective is Opus 4.6 at finding security vulnerabilities?
Why the Future of Intelligence Is Already Here | Alex Wissner-Gross | TEDxBoston
The future of intelligence is rapidly evolving with AI advancements, poised to transform numerous aspects of life, work, and existence, with exponential growth and sweeping changes expected in the near future.
## Questions to inspire discussion.
Strategic Investment & Career Focus.
🎯 Q: Which companies should I prioritize for investment or career opportunities in the AI era?
A: Focus on companies with the strongest AI models and those advancing energy abundance, as these will have the largest marginal impact on enabling the innermost loop of robots building fabs, chips, and AI data centers to accelerate exponentially.
Understanding Market Dynamics.

Physicists challenge a 200-year-old law of thermodynamics at the atomic scale
A long-standing law of thermodynamics turns out to have a loophole at the smallest scales. Researchers have shown that quantum engines made of correlated particles can exceed the traditional efficiency limit set by Carnot nearly 200 years ago. By tapping into quantum correlations, these engines can produce extra work beyond what heat alone allows. This could reshape how scientists design future nanoscale machines.
Two physicists at the University of Stuttgart have demonstrated that the Carnot principle, a foundational rule of thermodynamics, does not fully apply at the atomic scale when particles are physically linked (so-called correlated objects). Their findings suggest that this long-standing limit on efficiency breaks down for tiny systems governed by quantum effects. The work could help accelerate progress toward extremely small and energy-efficient quantum motors. The team published its mathematical proof in the journal Science Advances.
Traditional heat engines, such as internal combustion engines and steam turbines, operate by turning thermal energy into mechanical motion, or simply converting heat into movement. Over the past several years, advances in quantum mechanics have allowed researchers to shrink heat engines to microscopic dimensions.

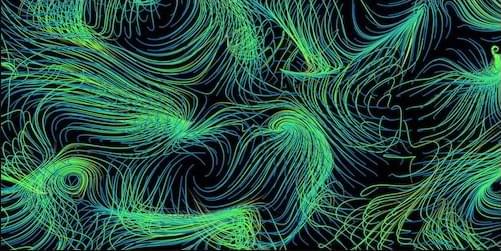
AI Discovers Geophysical Turbulence Model
One of the biggest challenges in climate science and weather forecasting is predicting the effects of turbulence at spatial scales smaller than the resolution of atmospheric and oceanic models. Simplified sets of equations known as closure models can predict the statistics of this “subgrid” turbulence, but existing closure models are prone to dynamic instabilities or fail to account for rare, high-energy events. Now Karan Jakhar at the University of Chicago and his colleagues have applied an artificial-intelligence (AI) tool to data generated by numerical simulations to uncover an improved closure model [1]. The finding, which the researchers subsequently verified with a mathematical derivation, offers insights into the multiscale dynamics of atmospheric and oceanic turbulence. It also illustrates that AI-generated prediction models need not be “black boxes,” but can be transparent and understandable.
The team trained their AI—a so-called equation-discovery tool—on “ground-truth” data that they generated by performing computationally costly, high-resolution numerical simulations of several 2D turbulent flows. The AI selected the smallest number of mathematical functions (from a library of 930 possibilities) that, in combination, could reproduce the statistical properties of the dataset. Previously, researchers have used this approach to reproduce only the spatial structure of small-scale turbulent flows. The tool used by Jakhar and collaborators filtered for functions that correctly represented not only the structure but also energy transfer between spatial scales.
They tested the performance of the resulting closure model by applying it to a computationally practical, low-resolution version of the dataset. The model accurately captured the detailed flow structures and energy transfers that appeared in the high-resolution ground-truth data. It also predicted statistically rare conditions corresponding to extreme-weather events, which have challenged previous models.