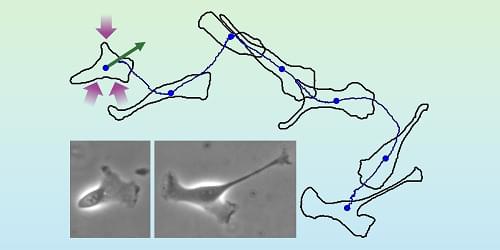
Researchers at the university of pennsylvania.
The University of Pennsylvania (Penn) is a prestigious private Ivy League research university located in Philadelphia, Pennsylvania. Founded in 1740 by Benjamin Franklin, Penn is one of the oldest universities in the United States. It is renowned for its strong emphasis on interdisciplinary education and its professional schools, including the Wharton School, one of the leading business schools globally. The university offers a wide range of undergraduate, graduate, and professional programs across various fields such as law, medicine, engineering, and arts and sciences. Penn is also known for its significant contributions to research, innovative teaching methods, and active campus life, making it a hub of academic and extracurricular activity.