
Modern technology allows us to measure magnetic fields created by electric signals in our brains. Now, a breakthrough makes detection 10 times better.
Modern technology allows us to measure magnetic fields created by electric signals in our brains. Now, a breakthrough makes detection 10 times better.
![]()
Meta, the Facebook parent company, has announced its new, artificial intelligence (AI)-driven language translation model, which claims to be able to translate 200 languages worldwide, in real-time. In a blog post from earlier today, Meta said that this is the first AI language translator model that brings a large number of fringe and lesser known languages from around the world — including fringe dialects from Asia and Africa.
The AI model can also carry out these translations without needing to first translate a language to English, and then translate it to the originally intended language. This, Meta said, does not only help in speeding up the translation time, but is a breakthrough of sorts since many of the 200 languages that its AI model can understand had little to no available public data for AI to train on.
The initiative is part of the company’s No Language Left Behind (NLLB) project, which it announced in February this year. The new AI model, called NLLB-200, has achieved up to 44% higher BLEU (Bilingual Evaluation Understudy) score in terms of its accuracy and quality of translation results. For Indian dialects, NLLB-200 is 70% better than existing AI models.
![]()
“We just open-sourced an AI model we built that can translate across 200 different languages — many which aren’t supported by current translation systems,” he said. “We call this project No Language Left Behind, and the AI modeling techniques we used from NLLB are helping us make high quality translations on Facebook and Instagram for languages spoken by billions of people around the world.”
Meta invests heavily in AI research, with hubs of scientists across the globe building realistic avatars for use in virtual worlds and tools to reduce hate speech across its platforms 0, among many other weird and wonderful things. This investment allows the company to ensure it stays at the cutting edge of innovation by working with the top AI researchers, while also maintaining a link with the wider research community by open-sourcing projects such as No Languages Left Behind.
The major challenge in creating a translation model that will work across rarer languages is that the researchers have a much smaller pool of data — in this case examples of sentences — to train the model versus, say, English. In many cases, they had to find people who spoke those languages to help them provide the data, and then check that the translations were correct.
Posted in innovation, space

It may seem like technology advances year after year, as if by magic. But behind every incremental improvement and breakthrough revolution is a team of scientists and engineers hard at work.
UC Santa Barbara Professor Ben Mazin is developing precision optical sensors for telescopes and observatories. In a paper published in Physical Review Letters, he and his team improved the spectra resolution of their superconducting sensor, a major step in their ultimate goal: analyzing the composition of exoplanets.
“We were able to roughly double the spectral resolving power of our detectors,” said first author Nicholas Zobrist, a doctoral student in the Mazin Lab.

Our ability to create nano scale products is getting better fast, and these breakthroughs could transform every industry from manufacturing to healthcare and beyond.

Intel Labs has announced that it has made a noteworthy advancement in the area of integrated photonics research, which it bills as the “next frontier” in expanding communications bandwidth between compute silicon in data centers and across networks. The company believes this advancement holds the promise of a future input/output (I/O) interface with improved energy efficiency and bandwidth, and a longer reach.
The disclosure explains the possibility to obtain well-matched output power in conjunction with uniform and densely spaced wavelengths, according to Haisheng Rong, Senior Principal Engineer at Intel Labs. Rong also points out that this can be done by utilizing existing manufacturing and process techniques in Intel fabs, and therefore ensures a path to volume production of the “next-generation co-packaged optics and optical compute interconnect at scale.”
Intel states that this breakthrough results in industry-leading advancements in multiwavelength integrated optics. It includes the demonstration of an eight-wavelength distributed feedback (DFB) laser array that is fully integrated on a silicon wafer and provides exceptional output power uniformity of +/-0.25 decibel (db), as well as wavelength spacing uniformity of +/-6.5% that go beyond industry specifications.

Or at least, they will be in the coming decades.
Cheap, plastic processors are the key to creating a whole new world of flexible tech, and luckily, there’s been a developmental breakthrough.

Attaining ‘sentience’ is not easy for an AI robot. Thousands of experts and researchers are working on AI and robots to crack the code and finally attain the one innovation that can change the entire course of the tech industry.
Posted in Elon Musk, innovation
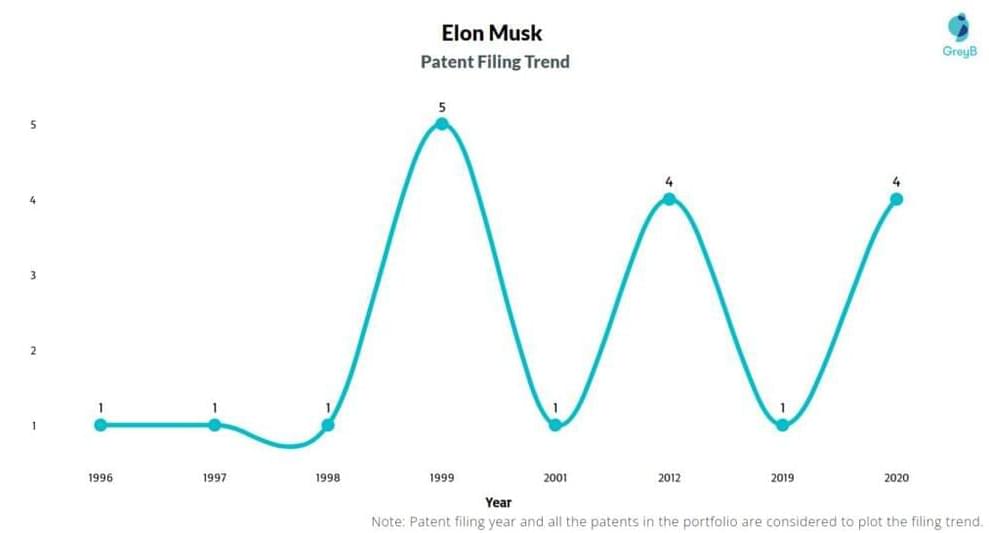
Chris ColeThat gets into that grey area of what is invention, what is refinement of process, promotion of process, etc.
I’ve not seen / aware of anything that jumps out as ‘invention’ with Musk.
Eric KlienAdmin.
Elon can do original stuff, he even wrote a game that he sold as a kid. Nowadays, he is CEO of many companies so he can make the decisions needed to move his companies forward. For me, the biggest thing he decided on was to use stainless steel instead … See more.

So how can LaMDA provide responses that might be perceived by a human user as conscious thought or introspection? Ironically, this is due to the corpus of training data used to train LaMDA and the associativity between potential human questions and possible machine responses. It all boils down to probabilities. The question is how those probabilities evolve such that a rational human interrogator can be confused as to the functionality of the machine?
This brings us to the need for improved “explainability” in AI. Complex artificial neural networks, the basis for a variety of useful AI systems, are capable of computing functions that are beyond the capabilities of a human being. In many cases, the neural network incorporates learning functions that enable adaptation to tasks outside the initial application for which the network was developed. However, the reasons why a neural network provides a specific output in response to a given input are often unclear, even indiscernible, leading to criticism of human dependence upon machines whose intrinsic logic is not properly understood. The size and scope of training data also introduce bias to the complex AI systems, yielding unexpected, erroneous, or confusing outputs to real-world input data. This has come to be referred to as the “black box” problem where a human user, or the AI developer, cannot determine why the AI system behaves as it does.
The case of LaMDA’s perceived consciousness appears no different from the case of Tay’s learned racism. Without sufficient scrutiny and understanding of how AI systems are trained, and without sufficient knowledge of why AI systems generate their outputs from the provided input data, it is possible for even an expert user to be uncertain as to why a machine responds as it does. Unless the need for an explanation of AI behavior is embedded throughout the design, development, testing, and deployment of the systems we will depend upon tomorrow, we will continue to be deceived by our inventions, like the blind interrogator in Turing’s game of deception.