AI-powered DIMON solves complex equations faster, boosting medical diagnostics and engineering simulations.


A new era in computing is emerging as researchers overcome the limitations of Moore’s Law through photonics.
This cutting-edge approach boosts processing speeds and slashes energy use, potentially revolutionizing AI and machine learning.
Machine learning is a subset of artificial intelligence (AI) that deals with the development of algorithms and statistical models that enable computers to learn from data and make predictions or decisions without being explicitly programmed to do so. Machine learning is used to identify patterns in data, classify data into different categories, or make predictions about future events. It can be categorized into three main types of learning: supervised, unsupervised and reinforcement learning.
Observing the effects of special relativity doesn’t necessarily require objects moving at a significant fraction of the speed of light. In fact, length contraction in special relativity explains how electromagnets work. A magnetic field is just an electric field seen from a different frame of reference.
So, when an electron moves in the electric field of another electron, this special relativistic effect results in the moving electron interacting with a magnetic field, and hence with the electron’s spin angular momentum.
The interaction of spin in a magnet field was, after all, how spin was discovered in the 1920 Stern Gerlach experiment. Eight years later, the pair spin-orbit interaction (or spin-orbit coupling) was made explicit by Gregory Breit in 1928 and then found in Dirac’s special relativistic quantum mechanics. This confirmed an equation for energy splitting of atomic energy levels developed by Llewellyn Thomas in 1926, due to 1) the special relativistic magnetic field seen by the electron due to its movement (“orbit”) around the positively charged nucleus, and 2) the electron’s spin magnetic moment interacting with this magnetic field.
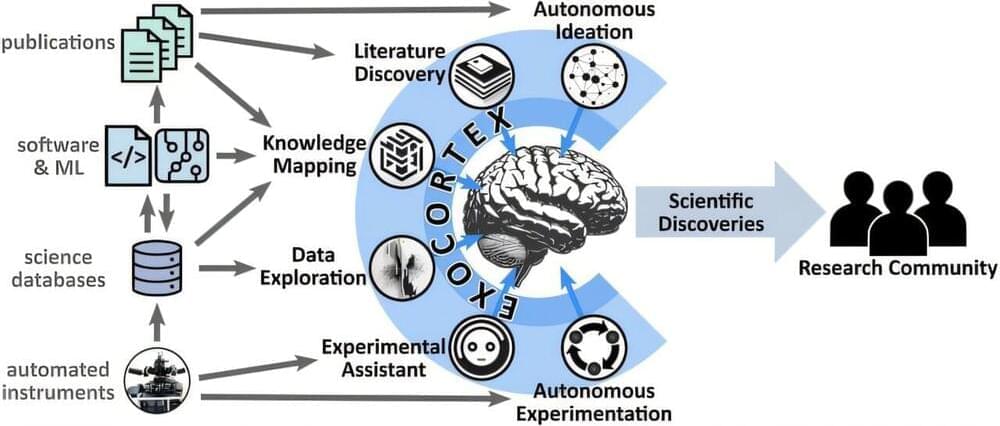
Artificial intelligence (AI) once seemed like a fantastical construct of science fiction, enabling characters to deploy spacecraft to neighboring galaxies with a casual command. Humanoid AIs even served as companions to otherwise lonely characters. Now, in the very real 21st century, AI is becoming part of everyday life, with tools like chatbots available and useful for everyday tasks like answering questions, improving writing, and solving mathematical equations.
AI does, however, have the potential to revolutionize scientific research —in ways that can feel like science fiction but are within reach.
At the U.S. Department of Energy’s (DOE) Brookhaven National Laboratory, scientists are already using AI to automate experiments and discover new materials. They’re even designing an AI scientific companion that communicates in ordinary language and helps conduct experiments. Kevin Yager, the Electronic Nanomaterials Group leader at the Center for Functional Nanomaterials (CFN), has articulated an overarching vision for the role of AI in scientific research.
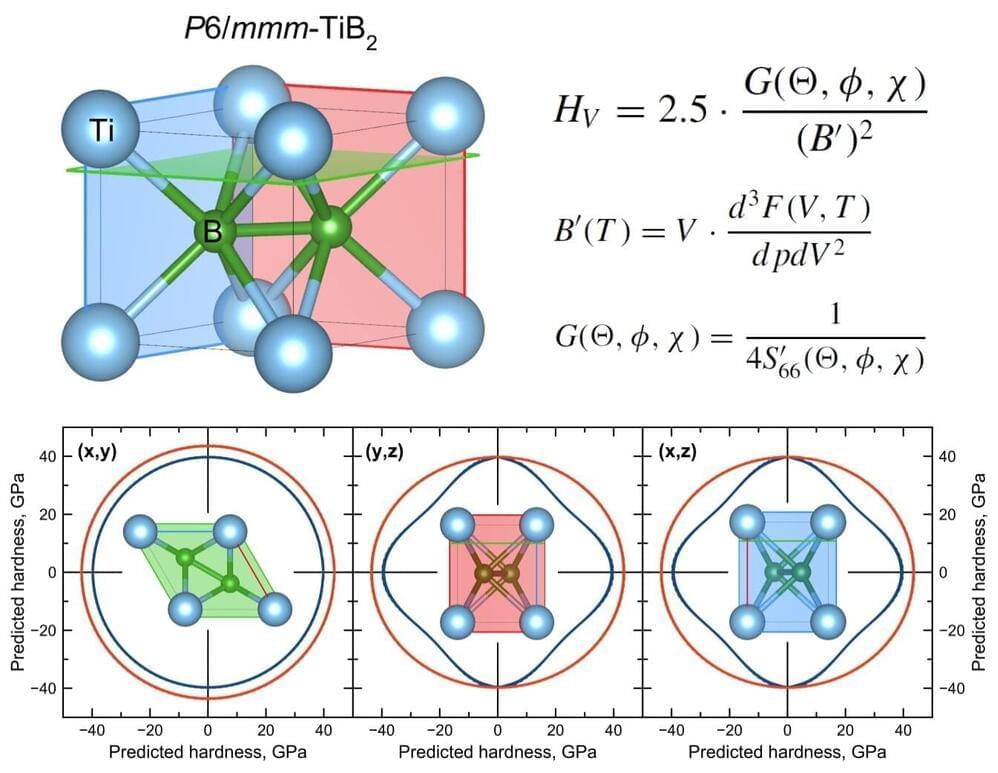
Physically Intuitive Anisotropic Model of Hardness https://arxiv.org/abs/2412.
Skoltech researchers have presented a new simple physical model for predicting the hardness of materials based on information about the shear modulus and equations of the state of crystal structures. The model is useful for a wide range of practical applications—all parameters in it can be determined through basic calculations or measured experimentally.
The results of the study are presented in the Physical Review Materials journal.
Hardness is an important property of materials that determines their ability to resist deformations and other damage (dents, scratches) due to external forces. It is typically determined by pressing the indenter into the test sample, and the indenter must be made of a harder material, usually diamond.

In a bold new theory, researchers from Microsoft, Brown University, and other institutions suggest that the universe might be capable of teaching itself how to evolve. Their study, published on the preprint server arXiv, proposes that the physical laws we observe today may have emerged through a gradual learning process, akin to Darwinian natural selection or self-learning algorithms in artificial intelligence.
This radical idea challenges traditional cosmology by imagining a primitive early universe where physical laws like gravity were far simpler or even static. Over time, these laws “learned” to adapt into more complex forms, enabling the structured universe we observe today. For instance, gravity might have initially lacked distinctions between celestial bodies like Earth and the Moon. This progression mirrors how adaptable traits in biology survive through natural selection.

It’s expected that the technology will tackle myriad problems that were once deemed impractical or even impossible to solve. Quantum computing promises huge leaps forward for fields spanning drug discovery and materials development to financial forecasting.
But just as exciting as quantum computing’s future are the breakthroughs already being made today in quantum hardware, error correction and algorithms.
NVIDIA is celebrating and exploring this remarkable progress in quantum computing by announcing its first Quantum Day at GTC 2025 on Thursday, March 20. This new focus area brings together leading experts for a comprehensive and balanced perspective on what businesses should expect from quantum computing in the coming decades — mapping the path toward useful quantum applications.

Quantum computing promises to solve complex problems exponentially faster than a classical computer, by using the principles of quantum mechanics to encode and manipulate information in quantum bits (qubits).
Qubits are the building blocks of a quantum computer. One challenge to scaling, however, is that qubits are highly sensitive to background noise and control imperfections, which introduce errors into the quantum operations and ultimately limit the complexity and duration of a quantum algorithm. To improve the situation, MIT researchers and researchers worldwide have continually focused on improving qubit performance.
In new work, using a superconducting qubit called fluxonium, MIT researchers in the Department of Physics, the Research Laboratory of Electronics (RLE), and the Department of Electrical Engineering and Computer Science (EECS) developed two new control techniques to achieve a world-record single-qubit fidelity of 99.998%. This result complements then-MIT researcher Leon Ding’s demonstration last year of a 99.92% two-qubit gate fidelity.
Quantum networking continues to encode information in polarization states due to ease and precision. The variable environmental polarization transformations induced by deployed fiber need correction for deployed quantum networking. Here, we present a method for automatic polarization compensation (APC) and demonstrate its performance on a metropolitan quantum network. Designing an APC involves many design decisions as indicated by the diversity of previous solutions in the literature. Our design leverages heterodyne detection of wavelength-multiplexed dim classical references for continuous high-bandwidth polarization measurements used by newly developed multi-axis (non-)linear control algorithm(s) for complete polarization channel stabilization with no downtime. This enables continuous relatively high-bandwidth correction without significant added noise from classical reference signals. We demonstrate the performance of our APC using a variety of classical and quantum characterizations. Finally, we use C-band and L-band APC versions to demonstrate continuous high-fidelity entanglement distribution on a metropolitan quantum network with an average relative fidelity of 0.94 ± 0.03 for over 30 hrs.
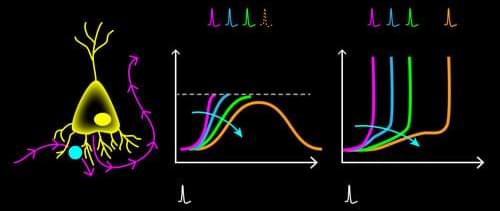
Artificial neural networks (ANNs) have brought about many stunning tools in the past decade, including the Nobel-Prize-winning AlphaFold model for protein-structure prediction [1]. However, this success comes with an ever-increasing economic and environmental cost: Processing the vast amounts of data for training such models on machine-learning tasks requires staggering amounts of energy [2]. As their name suggests, ANNs are computational algorithms that take inspiration from their biological counterparts. Despite some similarity between real and artificial neural networks, biological ones operate with an energy budget many orders of magnitude lower than ANNs. Their secret? Information is relayed among neurons via short electrical pulses, so-called spikes. The fact that information processing occurs through sparse patterns of electrical pulses leads to remarkable energy efficiency.
{kind=link}