Ultrasound-based irradiation of rock formations has attracted considerable attention as a technique for enhancing heavy-oil (high-viscosity crude oil) recovery from deep underground reservoirs. However, a unified theoretical framework for wave propagation and energy dissipation in these formations remains lacking because water coexists with heavy oil within rock pores, and gas bubbles in the water respond dynamically to ultrasonic excitation, thereby creating a complex system.
Conventional theories typically treat oil as a purely viscous (Newtonian) fluid or assume frequency ranges markedly below the ultrasonic regime. Consequently, these theories inadequately capture oil viscoelasticity and the influence of bubble oscillations in the ultrasonic regime.
Researchers at University of Tsukuba have developed a theoretical framework to clarify the propagation of ultrasonic waves through complex materials such as rocks containing mixtures of oil, water, and gas bubbles. The work extends previous low-frequency models and constructs a theoretical framework applicable to ultrasonic frequencies by incorporating three notable elements into a unified system of equations: (i) heavy-oil viscoelasticity, (ii) dynamic capillary pressure at fluid-fluid interfaces, and (iii) oscillations of gas bubbles dispersed in water induced by ultrasonic pressure fluctuations.
_____ This video is about how Divergence and Curl, along with the theory of Vector Analysis was discovered.
_____ Image Credits: https://commons.wikimedia.org/wiki/Fi…, https://creativecommons.org/licenses/.… Approaching a Black Hole: NASA’s Scientific Visualization Studio — Caltech-IPAC/Robert Hurt, Caltech-IPAC/Keith Miller, NASA/JPL/Chelsea Gohd, Global Science and Technology, Inc./Ella Kaplan, NASA/GSFC/Mark SubbaRao Many more images that are public domain from wikimedia commons _____ Sources: Vector, A Surprising Story of Space, Time, and Mathematical Transformation by Robyn Arianrhod A History of Vector Analysis by Michael J. Crose Maxwell’s Treatise on Electricity and Magnetism + A Dynamical Theory of the Electromagnetic Field Great videos by Kathy Loves Physics: • Quaternions are Amazing and so is William…, • How Maxwell’s Equations (and Quaternions)… _____ Corrections: 15:12 — on screen it should read “born in Scotland 1831″ instead of 1931 _____ Music: Epidemic Sound Animations created using Manim: https://www.manim.community/ Illustrations and Thumbnails: Christine Kosakowski This video was sponsored by Surfshark. https://commons.wikimedia.org/wiki/Fi…, https://creativecommons.org/licenses/.… Approaching a Black Hole: NASA’s Scientific Visualization Studio — Caltech-IPAC/Robert Hurt, Caltech-IPAC/Keith Miller, NASA/JPL/Chelsea Gohd, Global Science and Technology, Inc./Ella Kaplan, NASA/GSFC/Mark SubbaRao.
Many more images that are public domain from wikimedia commons.
Dr. Roman Yampolskiy joins me to explore one of the most urgent and uncomfortable questions of our time: what happens when we create intelligence that surpasses our own? We unpack the difference between the AI tools we use today and the emergence of artificial general intelligence, and why the transition from narrow systems to self-improving intelligence may mark a point where human control is no longer possible. Roman shares why even the people building these systems do not fully understand how they work, and why that gap in understanding becomes exponentially more dangerous as capabilities increase.
In this conversation, we explore the limits of control, prediction, and safety in a world where intelligence can recursively improve itself beyond human comprehension. Roman lays out why the problem of AI alignment may be fundamentally unsolvable, what timelines experts are realistically considering, and why even a single mistake at that level could have irreversible consequences. This episode invites a deeper reflection on what we are creating, what we assume we can control, and whether humanity is prepared for the intelligence it is bringing into existence.
André’s Book Recs: https://www.knowthyselfpodcast.com/bo… 00:00 Intro 01:25 What Is AGI and Why Should We Be Scared? 05:17 Roman’s Journey: From Optimism to Impossibility 09:07 The High Risk, Zero Reward Equation 13:01 Why Superintelligence Is Uncontrollable, Unexplainable, and Unverifiable 18:00 How Long Do We Have? The AGI Timeline 21:24 How Superintelligence Could Actually Kill Us 23:28 Are We Living in a Simulation? 28:21 Can AI Become Conscious? 31:28 Ad: BiOptimizers 32:41 The Possible Timelines: Terminator, the Matrix, or the Zoo 42:24 I-Risk, X-Risk, and S-Risk: Three Ways It Goes Wrong 46:31 The Human Meaning Crisis: Jobs, Purpose, and What’s Left 49:02 Ad: Based Bodyworks 50:20 What Empowers Us as Individuals Right Now 59:37 The Race to Doom: Who’s Building It and Why They Won’t Stop 1:07:41 Can AI Be Conscious — and Does It Already Have Internal Experiences? 1:12:41 Hacking the Simulation: Quantum, DMT, and Escaping the Code 1:18:30 Simulation Theory, Religion, and the Same Ancient Map 1:29:34 The Deal Roman Would Offer Altman, Dario, and Elon 1:39:44 What Is Humor? A Computer Scientist’s Theory 1:43:03 What Comes After: Singularity, Death, and Knowing Thyself ___________ Episode Resources: https://www.romanyampolskiy.com/https://www.amazon.com/Unexplainable-?tag=lifeboatfound-20… / andreduqum / knowthyself / @knowthyselfpodcasthttps://www.knowthyselfpodcast.com Listen to the show: Spotify: https://spoti.fi/4bZMq9l Apple: https://apple.co/4iATICX
___________ 00:00 Intro 01:25 What Is AGI and Why Should We Be Scared? 05:17 Roman’s Journey: From Optimism to Impossibility 09:07 The High Risk, Zero Reward Equation 13:01 Why Superintelligence Is Uncontrollable, Unexplainable, and Unverifiable 18:00 How Long Do We Have? The AGI Timeline 21:24 How Superintelligence Could Actually Kill Us 23:28 Are We Living in a Simulation? 28:21 Can AI Become Conscious? 31:28 Ad: BiOptimizers 32:41 The Possible Timelines: Terminator, the Matrix, or the Zoo 42:24 I-Risk, X-Risk, and S-Risk: Three Ways It Goes Wrong 46:31 The Human Meaning Crisis: Jobs, Purpose, and What’s Left 49:02 Ad: Based Bodyworks 50:20 What Empowers Us as Individuals Right Now 59:37 The Race to Doom: Who’s Building It and Why They Won’t Stop 1:07:41 Can AI Be Conscious — and Does It Already Have Internal Experiences? 1:12:41 Hacking the Simulation: Quantum, DMT, and Escaping the Code 1:18:30 Simulation Theory, Religion, and the Same Ancient Map 1:29:34 The Deal Roman Would Offer Altman, Dario, and Elon 1:39:44 What Is Humor? A Computer Scientist’s Theory 1:43:03 What Comes After: Singularity, Death, and Knowing Thyself ___________.
🧠⚛️ Beyond Penrose: Can Consciousness Be Derived from Geometry? For more than 30 years, Roger Penrose and Stuart Hameroff proposed that consciousness emerges through Objective Reduction (OR) inside neuronal microtubules. Penrose’s key equation is remarkably simple: τ_OR = ℏ / E_G where: τ_OR = collapse time ℏ = reduced Planck constant E_G = gravitational self-energy of the spacetime superposition The idea is: 🌌 Spacetime superposition ⟶ Gravitational instability ⟶ Wavefunction collapse ⟶ Conscious event But a major question remained: ❓ What is the mathematical mechanism that actually causes collapse? The EWOG framework attempts to provide one.
Take back your personal data with Incogni! Use code Sabine at the link below and get 60% off annual plans: https://incogni.com/sabine.
As AI continues to improve its reasoning abilities, mathematicians are increasingly worried about the computer algorithms replacing them. In late May, those fears got even worse when OpenAI revealed that one of its general-purpose reasoning models had written a proof solving a math problem that’s sat unsolved for more than 80 years. But should they actually be worried? Let’s take a look.
Pengfei Sun et al. develop a spiking neural network with a dual memory pathway, co-designed with a custom neuromorphic chip. The approach delivers over 4× throughput and 5x energy efficiency gains while using 40–60% fewer parameters than state-of-the-art implementations.
The experiment addresses a long-standing question in physics — in some theories of the universe, there is no built‑in clock so how do you tell what comes ‘before’ and ‘after’ without external time?
Professor Barontini showed that the system follows the standard equations of quantum physics and demonstrates that deep questions about the nature of time — usually discussed only in theories about the universe as a whole — can be tested in controlled laboratory experiments.
The experiment provides a powerful testbed for ideas in quantum cosmology and gravity, meaning that ideas relating to the early universe can now be tested experimentally in the lab.
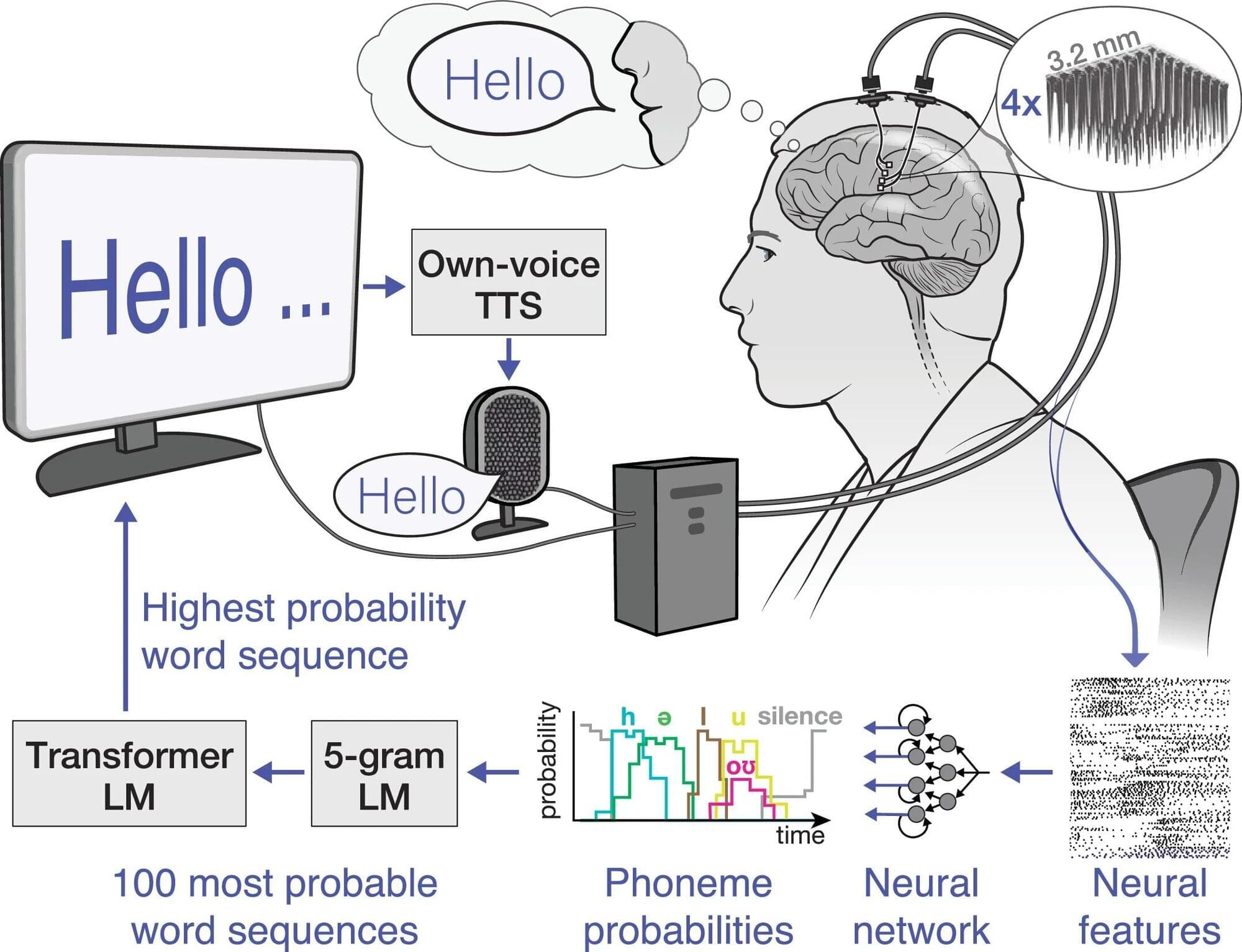
A new study demonstrates that a person with severe paralysis caused by amyotrophic lateral sclerosis (ALS) can use a brain-computer interface (BCI) at home to communicate, work and interact with the digital world—without the need for researcher support. Published in Nature Medicine, the results mark a significant step toward delivering practical assistive technology for people with severe speech and motor impairments.
The BCI system was developed at UC Davis, in collaboration with colleagues at Brown University and Mass General Brigham Neuroscience Institute. It is equipped with advanced decoding algorithms that translate neural signals into text (speech BCI) and enable cursor control (movement BCI). It allows full interaction with a personal computer.
The brain-computer interface is designed to restore communication and computer control by decoding neural activity linked to attempted speech and movement. Although recent advances have achieved high accuracy in research settings, real-world adoption has been limited by two key challenges: independent at-home use and reliable long-term performance.
His revolutionary idea? Before “computer science” was even a field, Church invented the lambda calculus (λ-calculus)—an elegant, abstract system for expressing computation through pure mathematical functions. In 1936, he used it to prove that no universal algorithm could ever decide the truth of all mathematical statements, solving Hilbert’s famous Entscheidungsproblem in the negative. This became known as Church’s Theorem, and it revealed something profound: there are hard limits to what any machine can compute.
That same year, Church articulated what we now call the Church–Turing thesis: any problem that can be “effectively calculated” can be computed by a Turing machine—or equivalently, expressed in lambda calculus. When Alan Turing learned of Church’s work, he traveled to Princeton to study under him. Together, they proved their two seemingly different models of computation were fundamentally equivalent, laying the bedrock for all future computer science.
Alonzo Church was born on June 14, 1903, in Washington, D.C., where his father, Samuel Robbins Church, was a justice of the peace [ 5 ] and the judge of the Municipal Court for the District of Columbia. He was the grandson of Alonzo Webster Church (1829−1909), United States Senate Librarian from 1881 to 1901, and great-grandson of Alonzo Church, a professor of Mathematics and Astronomy and 6th President of the University of Georgia. [ 6 ] As a young boy, Church was partially blinded by an air gun accident. [ 7 ] The family later moved to Virginia after his father lost his position at the university because of failing eyesight. With help from his uncle, also named Alonzo Church, the son attended the private Ridgefield School for Boys in Ridgefield, Connecticut. [ 8 ] After graduating from Ridgefield in 1920, Church attended Princeton University, where he was an exceptional student. He published his first paper on Lorentz transformations [ 9 ] in 1924 and graduated the same year with a degree in mathematics. He stayed at Princeton for graduate work, earning a Ph. D. in mathematics in three years under Oswald Veblen.
He married Mary Julia Kuczinski in 1925. The couple had three children: Alonzo Jr. (1929), Mary Ann (1933), and Mildred (1938).