UB physicists have upgraded an old quantum shortcut, allowing ordinary laptops to solve problems that once needed supercomputers. A team at the University at Buffalo has made it possible to simulate complex quantum systems without needing a supercomputer. By expanding the truncated Wigner approximation, they’ve created an accessible, efficient way to model real-world quantum behavior. Their method translates dense equations into a ready-to-use format that runs on ordinary computers. It could transform how physicists explore quantum phenomena.
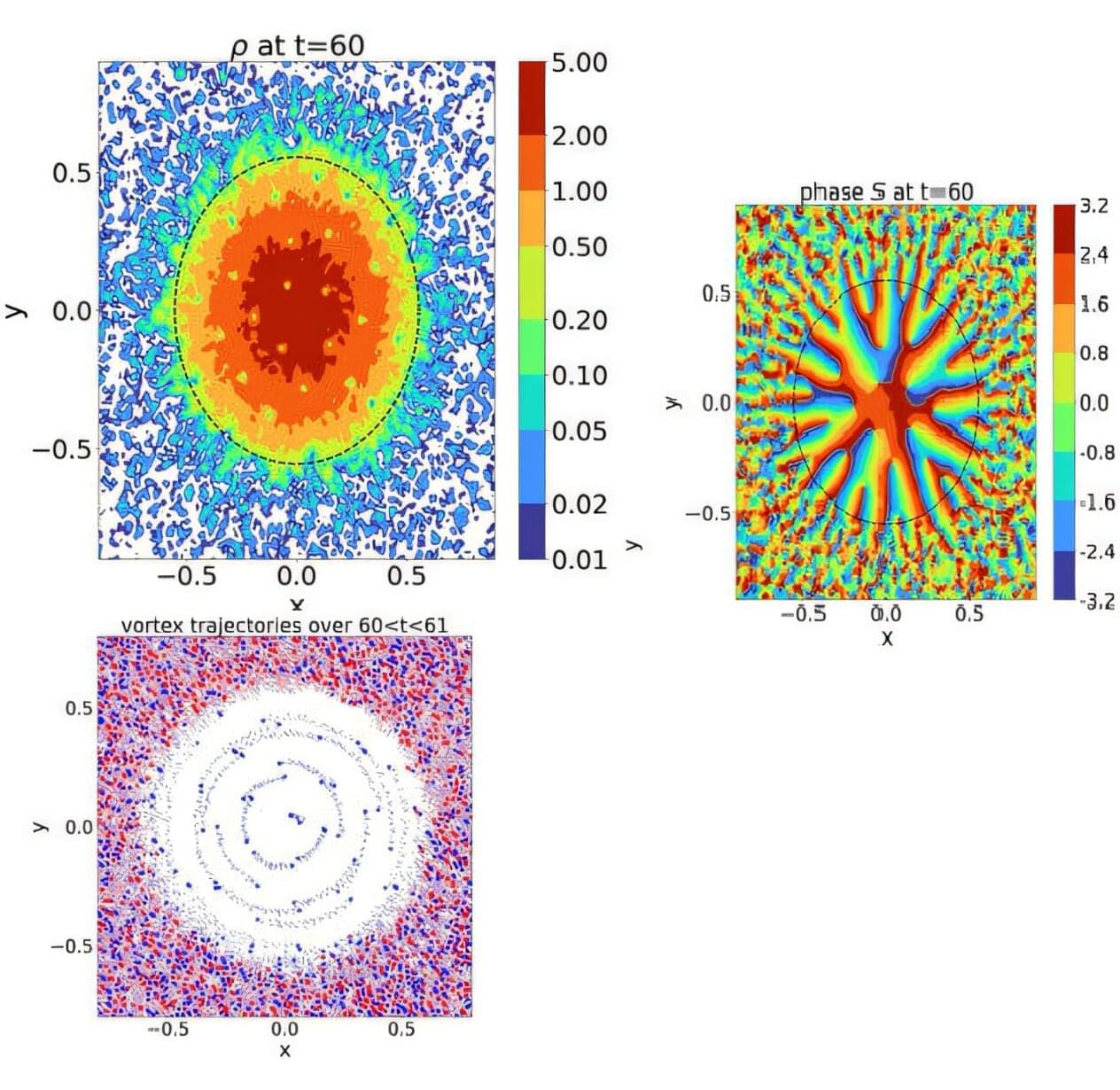
Picture diving deep into the quantum realm, where unimaginably small particles can exist and interact in more than a trillion possible ways at the same time.
It’s as complex as it sounds. To understand these mind-bending systems and their countless configurations, physicists usually turn to powerful supercomputers or artificial intelligence for help.