Numerous natural language processing (NLP) applications have benefited greatly from using large language models (LLMs). While LLMs have improved in performance and gained additional capabilities due to being scaled, they still have a problem with “hallucinating” or producing information inconsistent with the real-world facts detected during pre-training. This represents a significant barrier to adoption for high-stakes applications (such as those found in clinical and legal settings), where the generation of trustworthy text is essential.
The maximum likelihood language modeling target, which seeks to minimize the forward KL divergence between the data and model distributions, may be to blame for LMs’ hallucinations. However, this is far from certain. The LM may assign a non-zero probability to phrases that are not fully consistent with the knowledge encoded in the training data if this goal is pursued.
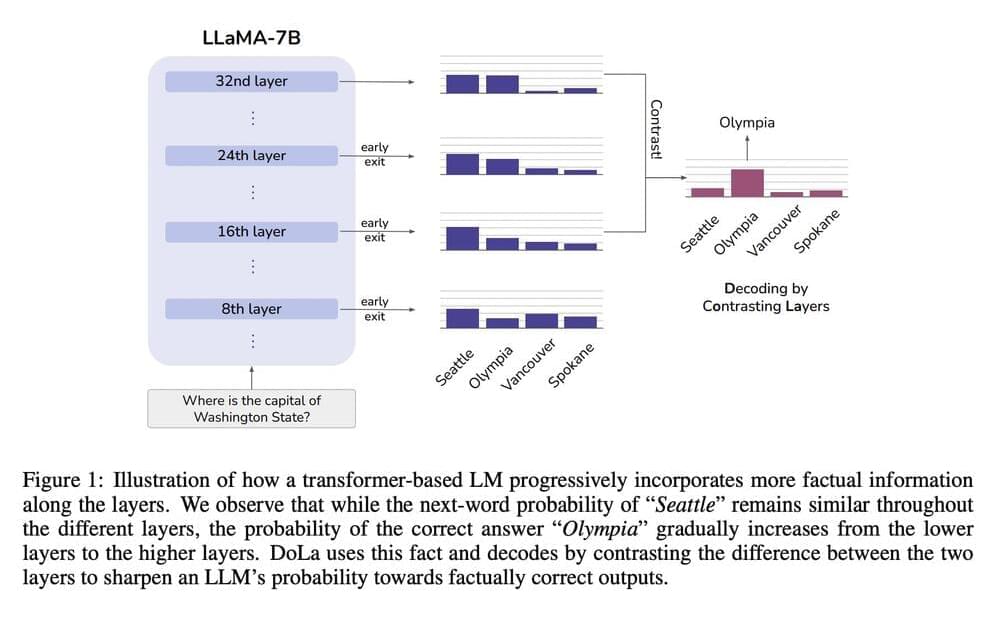
From the perspective of the interpretability of the model, studies have shown that the earlier layers of transformer LMs encode “lower level” information (such as part-of-speech tags). In contrast, the later levels encode more “semantic” information.