Human beings are capable of processing several sound sources at once, both in terms of musical composition or synthesis and analysis, i.e., source separation. In other words, human brains can separate individual sound sources from a mixture and vice versa, i.e., synthesize several sound sources to form a coherent combination. When it comes to mathematically expressing this knowledge, researchers use the joint probability density of sources. For instance, musical mixtures have a context such that the joint probability density of sources does not factorize into the product of individual sources.
A deep learning model that can synthesize many sources into a coherent mixture and separate the individual sources from a mixture does not exist currently. When it comes to musical composition or generation tasks, models directly learn the distribution over the mixtures, offering accurate modeling of the mixture but losing all knowledge of the individual sources. Models for source separation, in contrast, learn a single model for each source distribution and condition on the mixture at inference time. Thus, all the crucial details regarding the interdependence of the sources are lost. It is difficult to generate mixtures in either scenario.
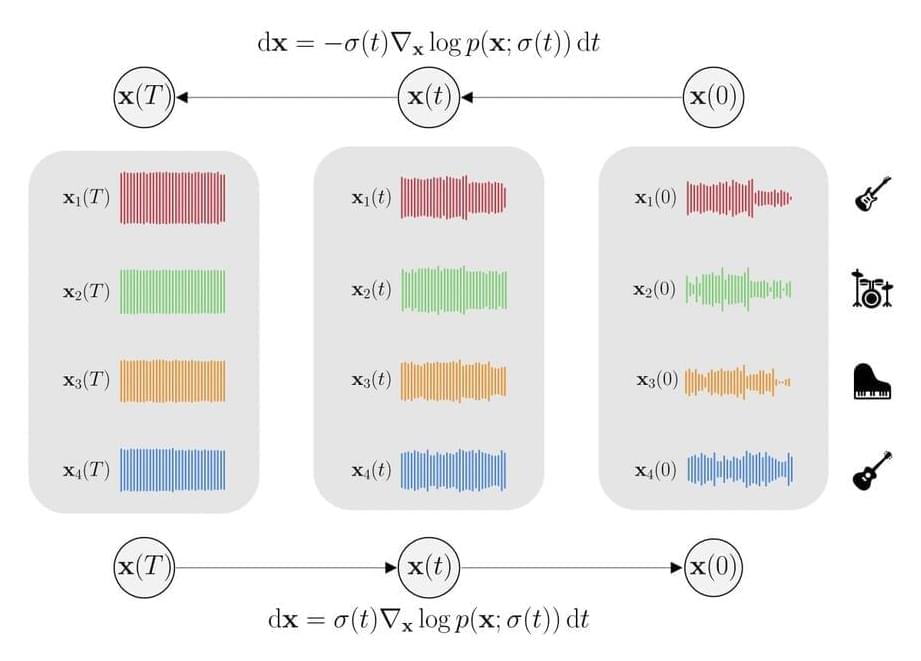
Taking a step towards building a deep learning model that is capable of performing both source separation and music generation, researchers from the GLADIA Research Lab, University of Rome, have developed Multi-Source Diffusion Model (MSDM). The model is trained using the joint probability density of sources sharing a context, referred to as the prior distribution. The generation task is carried out by sampling using the prior, whereas the separation task is carried out by conditioning the prior distribution on the mixture and then sampling from the resulting posterior distribution. This approach is a significant first step towards universal audio models because it is a first-of-its-kind model that is capable of performing both generation and separation tasks.