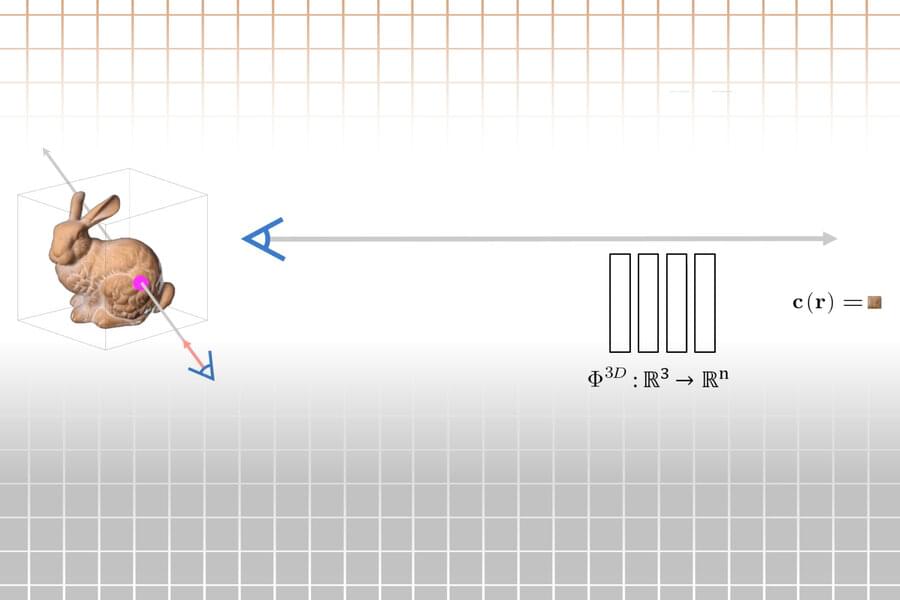
Humans are pretty good at looking at a single two-dimensional image and understanding the full three-dimensional scene that it captures. Artificial intelligence agents are not.
Yet a machine that needs to interact with objects in the world—like a robot designed to harvest crops or assist with surgery—must be able to infer properties about a 3D scene from observations of the 2D images it’s trained on.
While scientists have had success using neural networks to infer representations of 3D scenes from images, these machine learning methods aren’t fast enough to make them feasible for many real-world applications.