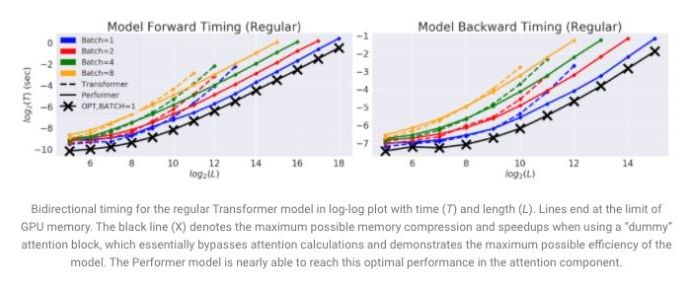
{kind=link}
Transformer model, a deep learning framework, has achieved state-of-the-art results across diverse domains, including natural language, conversation, images, and even music. The core block of any Transformer architecture is the attention module, which computes similarity scores for all pairs of positions in an input sequence. Since it requires quadratic computation time and quadratic memory size of the storing matrix, with the increase in the input sequence’s length, its efficiency decreases.
Thus, for long-range attention, one of the most common methods is sparse attention. It reduces the complexity by computing selective similarity scores from the sequence, based on various methods. There are still certain limitations like unavailability of efficient sparse-matrix multiplication operations on all accelerators, lack of theoretical guarantees, insufficiency to address the full range of problems, etc.